Manual and Automated Systems Examination
CHAPTER SYNOPSIS
If the determination has been made to develop an automated system, the analyst must evaluate the various issues of automation. These include among others: Should micro, mini, or mainframe systems be developed? Should they be on-line or batch? Should they be stand-alone or integrated? Should the firm build the application in-house or should it attempt to buy a package commercially? Other issues include resident machine size, package evaluation, and selection.
This chapter discusses the various parameter decisions, tradeoffs, advantages, and disadvantages for the issues discussed above. In addition, where appropriate, there are lists of questions and issues which need to be addressed.
Top-Down versus Bottom-Up Analysis
Top-down analysis
Top-down analysis is a term used to describe analysis which starts with a high level overview of the firm and its functional areas. This overview should be a complete picture of the firm, but it should be general rather than very detailed. Once the overview has been developed, the analyst produces successively more detailed views of specific areas of interest. This process of developing more and more detailed views is called decomposition.
Top-down analysis is the method used by most major commercial methodologies and is considered to be the most thorough form of analysis. The order of the life cycle phases discussed earlier is based on a top-down analysis.
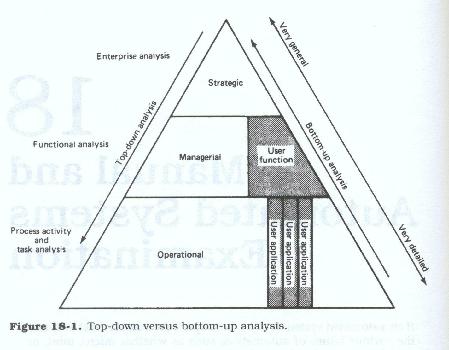
The difference between top-down and bottom-up analysis can be illustrated in the following manner (see Figure 18.1). Top-down analysis takes a finished product and attempts to find out how it works. The product is taken apart; the atomic parts used to create it are examined and documented, subassembly by subassembly. Bottom-up analysis starts with the gathering of all the atomic parts; the analyst then attempts to figure out what they will look like when they are all assembled and what the completed product can and should do.
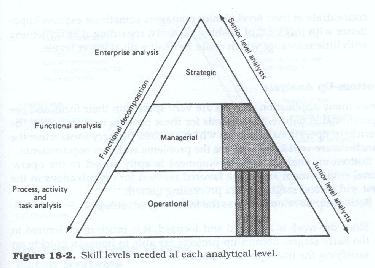
The top-down method of analysis is usually accomplished in a phased manner. Many times the various phases are worked on by different teams, or by different people from the same teams. The work is assigned to correspond to the perceived skill levels required (Figure 18.2). The senior analysts work on the higher levels, while the junior analysts typically work on the lower levels.
The advantages of top-down analysis are
The disadvantages of top-down are:
Bottom-up analysis
Since many application projects are very specific in their focus and are operational in nature, the analysis for these projects may start with the clerical or operational activities which are their primary focus. Here the functions are well known as are the problems and user requirements.
Bottom-up analysis and development is aptly suited to the operational environment and is the favored method for organizations in the first and second stages of data processing growth.
Bottom-up development has the following advantages.
The disadvantages of bottom-up projects are
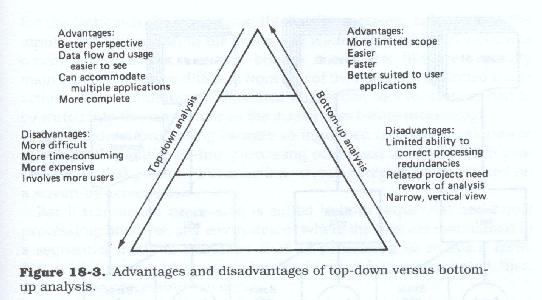
The advantages and disadvantages of top-down and bottom-up analysis are presented in Figure 18.3.
On-line versus Batch Systems
Early systems development, being limited by both technological availability and analytical experience, tended to duplicate the sequential batch processing which itself was a holdover from the early manufacturing experiences. Work flows were treated as step-by-step processing governed by strict rules of precedence.
The methods of data entry and automated input required strict controls to ensure that all inputs were received and entered properly. These controls were necessary because of the time delays between acquisition of the source data and their actual entry into the automated files.
Additionally because of the number of processing steps, such as keypunching, sorting, and collating of the data, occurring prior to the actual machine processing, the possibility and probability of data being incorrect or of items being lost were rather high. To alleviate these problems, analysts developed additional manual and automated steps and inserted them into the processing streams for collecting input items into groups, called batches, developing control totals on both the number of items and the quantity and dollar amounts of those items. As each batch was collected and verified it was processed against the master files. This type of processing tended to become somewhat start-stop in nature. Batches tended to be processed together, which required further controls on the number of batches and on overall batch totals. See Figure 18.4 for a description of the sequence of batch processing.
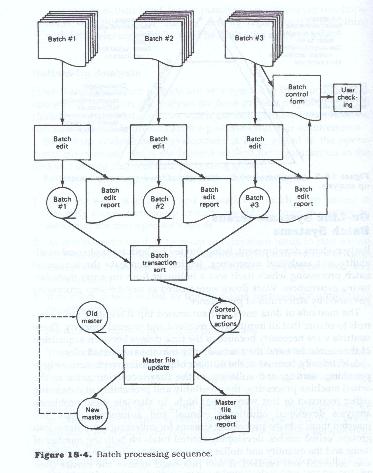
Since processing could not be complete until all batches were processed, any activities on the file as a whole, or on all transactions, tended to wait for the last batch. In some cases, the batch processing only verified the inputs, and transaction-to-file processing waited until all batch work was completed. This was necessary because the master files were usually maintained in an order different from that of the randomly collected transactions. These randomly accumulated transaction files themselves had to be sorted into the same order as the master files before processing.
This mode of processing became so ingrained into the development mentality that initial on-line processing continued to mimic batch processing, in that groups of transactions were aggregated and entered on a screen by screen basis.
Batch transaction processing is suited to both sequential and direct processing; however any environment where the files are maintained in a sequential medium mandates that all processing be in batch form. Where the master files are maintained in random-access--based files, true on-line processing can occur.
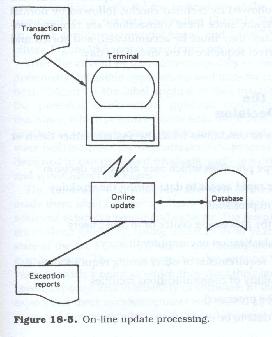
On-line processing is usually characterized by transaction-at-a-time designs, where the transaction data directly updates the master file in a random manner (Figure 18.5). In this mode, the user is presented with a screen which allows the entry of a single transaction of data. That data is verified independently and applied to the master file. On-line processing is random in nature and is based upon transaction arrival, while batch processing waits for a sufficient number of transactions to arrive to make up a batch.
Batch processing takes advantage of the fact that task setup usually takes as much as if not more time than does the actual processing. Thus if multiple transactions can be processed with one setup, time will be saved. This is the assembly line theory. On the other hand, on-line is similar to the artisan method where one person performs a complete sequence of tasks.
In many cases however, batch processing is required by business rules and policies. For instance:
Issues Affecting the On-line versus Batch Decision
Mainframe, Mini, and Micro Systems
Prior to the late 1970s and early 1980s, the choice of automated system implementation environment was limited to centralized hardware, which bore the labels "mainframe" and "minicomputer." These labels usually referred to distinctions in both size and power. The "mini" label was usually applied to that hardware which was obtained for standalone or "turnkey" systems. A turnkey system was a standalone system which was acquired as a complete package of hardware and software.
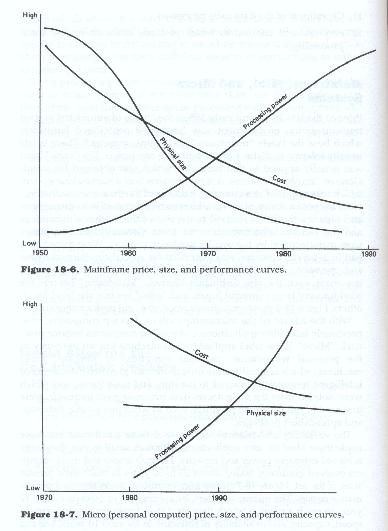
As the performance of systems increased in terms of both throughput and capacity, the labels referred to the size of both of the machines themselves and to the vendors who manufactured them. Generally, minicomputers were manufactured by the smaller hardware vendors. What these boxes had in common, however, was their need for special conditioned rooms and operations staffs. As the technology of the manufacturing process improved, even the size distinction blurred. "Mainframe" became the label for very large powerful boxes and "mini" became the label for all others. Figure 18.6 shows mainframe price, size, and performance curves.
With the advent of the micro- or desktop computers, new, previously infeasible applications and uses for computers became practical. "Micro" is the label applied to that machine known variously as the personal workstation, personal computer, or desktop. These machines, which originally were little more than glorified calculators or intelligent terminals compared to the mini and mainframe, and which were isolated from the mainstream data processing environment, were designed to run packaged products, such as word processing, database, and spreadsheet packages.
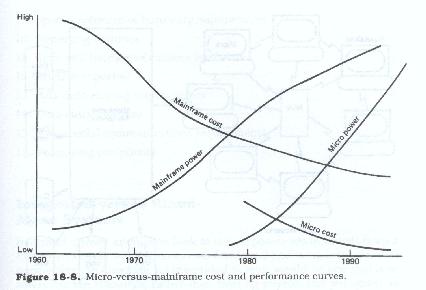
The versatility and relatively low cost of these small machines have made them ideal for user applications. While small in size, they have achieved extensive power and capacity. The evolution of the mainframe and minicomputers took about 25 to 30 years to reach their present state. Figure 18.7 shows microcomputer price, size, and performance curves. The microcomputers by contrast have taken less than 10 years to reach a point where they rival their larger cousins in terms of speed, capacity, and availability of software. In the next 10 years, one can expect that these microcomputers will exceed all but the largest and most powerful supercomputers in speed and capacity and will have data storage capability to rival many present-day machines. Figure 18.8 is a comparison of microcomputer versus mainframe price-performance curves.
The rapid development of these very small machines has opened up new areas of automation within companies and has placed many firms back into the first stages of a new data processing growth cycle. Additionally, applications which were previously only available on mainframes have been made available on the micros, leading to intense reautomation efforts in an effort to take advantage of these inexpensive, personal machines.
The development of packaged applications for record keeping and analysis and for routine and highly specialized business processing support has made these machines relatively common office tools. As their capacity and speed increase and as their cost decreases, more and more applications will be found for them. The analyst must seriously consider this new and wide range of machinery when looking to create a practical business solution for the client-user area.
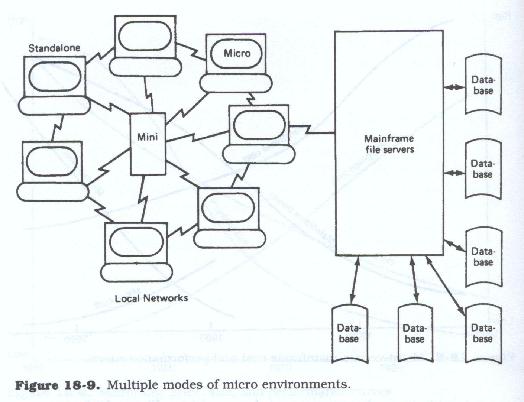
Although microcomputers were originally designed as stand-alone, personal machines, the tediousness of manual data entry has caused both the business and personal user communities to demand and get the capability to move data to and from the mainframes on a direct, automated basis. Although, currently there are format and speed restrictions, it is conceivable that in the very near future data will move freely and quickly between the two environments, opening up vast opportunities for cost-effective automation for the user areas. The dual mode capability, local and remote, plus the growing ability to network, that is, interconnect, these machines, many of them with common libraries and common data storage, will further open up these machines to application use. Figure 18.9 shows the multiple modes of microcomputer environments.
Micro, Mini, or Mainframe Issues
Integrated Systems versus Stand-Alone
Integrated systems are those which attempt to look at the corporate environment from a top-down viewpoint or from a cross-functional and cross--business-unit perspective. To illustrate, an integrated system would be one which looks at human resources, rather than treating payroll and personnel as separate processes, or at general ledger rather than at balance sheet, accounts payable, and accounts receivable, etc. Integrated systems are modeled along functional, business, and strategic lines rather than along process and operational lines. Figure 18.10 compares stand-alone and integrated systems.
Integrated systems recognize the interdependency of user areas and try to address as many of these interrelated interdependent areas as is feasible. Integrated systems are usually oriented along common functional and data requirement lines. Integrated systems require top-down analysis and development since it is easier to determine overall requirements, and also because integrated systems development makes it necessary to understand the interdependencies and interrelated nature of the various applications which must be hooked together to achieve integration. The scope and requirements of integrated systems are difficult to analyze and generally require more time to develop.
Since integrated systems cross functional, and thus user, boundaries, many user areas must be involved in both the analysis and subsequent design and implementation phases. A multi-user environment is much more difficult to work with because even though the system is integrated, the users normally are not. Each user brings his or her own perspective to the environment, problems, and requirements, and these differing perspectives may often conflict with each other. The analyst must resolve these conflicts during the analysis process, or during the later review and approval cycles. In addition to the conflicting perspectives, there are normally conflicting system goals, and, more important, conflicting time frames as well.
Stand-alone systems, by contrast, are usually those which are self-contained and are designed to accomplish a specific process or support a specific function. Stand-alone systems are usually characterized by a single homogeneous user community, limited system goals, and a single time frame.
There are no guidelines which distinguish stand-alone systems from integrated ones. In fact, stand-alone systems may also be integrated in nature. There are also no size or complexity distinguishing characteristics.
The decision as to whether to attempt to develop an integrated system or to develop a stand-alone system is dependent upon the following issues.
Make versus buy decisions
Once the list of change requirements and specifications is completed and the list proposed systems change solutions (not the design itself) have been identified and prioritized, one last set of tasks faces the analysis team. That is, to determine whether it is feasible to obtain from a commercial vendor, a prepackaged application system which will accomplish a large enough number of changes, in a viable, acceptable and cost effective manner, as opposed to attempting the design and development of a system using internal resources.
This analysis is called the "Make versus Buy" decision. In many cases the feasibility of obtaining a pre-built package is extremely cost-effective.
The make or buy decision may also extend to retaining an outside firm to custom-build a package to the user's specifications.
Using the analysis documentation of the current system, which is the base upon which to apply the changes, and the change requirements and specifications developed in the Examination and Study phase, the analysis and design team (including the user representatives) must examine and arrive at an answer to each of the following make versus buy issues.
Make-versus-Buy Issues
Package Evaluation and Selection
If the decision has been reached to buy, the analyst must recognize that any system that is acquired, rather than custom-built, will not fully meet the firm's needs. Pre-built packages are by their very nature generalized to suit the largest number of potential customers. This implies that while most packages will address the basic functional requirements, some percentage of the needed user functionality will be missing. Each package will have its own configuration of supported functions and these may not be the same from package to package. Those functions which are supported, basic or otherwise, can also be implemented in sometimes radically different ways, and the depth and comprehensiveness of the functional support can also differ radically.
Additionally there may be some specialized company functional needs which may not be addressed by any vendor package. The analyst can also expect that each package will support not only different functional requirements but may also be designed to operate in markedly different types of businesses. For instance a financial package designed for manufacturing organizations will have different design characteristics from one designed for a financial or service organization. This difference in functionality may make comparative product evaluation difficult if not impossible.
Most packages were originally designed for a specific company in a specific industry and were then generalized for commercial sale. These packages may have been designed by the specific firm itself or designed for the firm by an outside service consultant. Depending upon its origins, the implementation may vary from very good to very poor, and the documentation can be expected to vary a great deal. In any case, because of their origins as custom systems, one can expect the implementation to bear a strong imprint of the original users.
Industry surveys indicate that a functional and procedural "fit" of between 30 to 40 percent is considered average. This means that 30 to 40 percent of the package capability will exactly match the company's requirements. The analyst must assess the closeness of the fit between desired and needed functionality. The analyst must also assess the closeness of the procedural implementation to the way the firm currently does business and assess the impact of either modifying the firm to conform to the package requirements or modifying the package to conform to the firm's requirements.
In addition, the analyst must "look beneath the covers" at how the system works, not only what it does. Many packages come with their own forms, coding structures, processing algorithms, and built-in standards and policies. Many of these package internals are not changeable, and the analyst must determine the degree to which the user is willing to accept them (Figure 18.11). The analysis must also examine in detail the vendor of the product, the vendor's service and reliability, and any vendor restrictions on the company's use of the product. The lack of available literature and of available detailed evaluation information may make this evaluation process very time-consuming.
Examining the Buy Option
Some issues to consider when examining the buy option are
Client server specific issues:
A Professional's Guide to Systems Analysis, Second Edition
Written by Martin E. Modell
Copyright © 2007 Martin E. Modell
All rights reserved. Printed in the United States of America. Except as permitted under United States Copyright Act of 1976, no part of this publication may be reproduced or distributed in any form or by any means, or stored in a data base or retrieval system, without the prior written permission of the author.