Activity or Task Analysis
CHAPTER SYNOPSIS
A task is the lowest unit of work within the scope of the analysis.Task analysis is the final level of system decomposition. These tasks may be performed in a manual, automated, or semi-automatic manner. Each task has one or more inputs, some processing, and some outputs. The analyst must carefully examine the individual tasks being performed by the user to determine how, when, why, and under what conditions the task is to be performed.
This chapter discusses the concept of a business task and provides some insight into its identification and documentation. It includes extensive lists of questions for the analyst to ask when interviewing at the task level.
What Is a Task?
A definition
A task is the lowest unit of discrete work which can be identified. An activity may be composed of many tasks. Tasks are highly repetitive, highly formalized, and rigidly defined.
Business Task Analysis
A task is the lowest unit of work within the scope of the analysis. Task analysis is the final level of system decomposition. These tasks may be performed in a manual, automated, or semi-automated manner. Each task has one or more inputs, some processing, and some outputs. The analyst must carefully examine the individual tasks being performed by the user to determine how, when, why, and under what conditions the task is to be performed.
Although it is not the analyst's goal to perform the user's work, the analyst must know as much as, if not more than, any individual user about the actual mechanics and rationale of that work. Many analysts concentrate on the mechanical aspects of the task performed by the user and thus develop automated systems which replicate those tasks within the machines. While understanding the task mechanics is important and automation of those tasks is a goal, it is also vital to understand why those tasks are being performed and what the effect of that task performance is on other tasks within the immediate user area and its larger impact on the firm.
No task exists or should exist in a vacuum. Tasks are performed for a business reason, and the specific manner in which they are performed also has a business reason. The determination of those business reasons is as much a part of the analysis process as is the determination of the task mechanics. Task analysis is not usually performed as a specific step within the overall analysis phase, but it is usually combined with the process analysis activities. It is presented separately for clarity and to highlight task-specific questions.
The analyst must remain aware of a basic fact of business systems: Tasks are added to business systems as the need arises, usually with no overall plan in mind. The need is recognized, analyzed (it is hoped), a procedure written (although not always), and someone is (always) assigned to the new job. These tasks, or jobs, "grow like Topsy. " In many instances what were understood to be one-time, or limited-term, tasks become institutionalized. These jobs may be added to existing process flows, but, more likely, new process flows are created and "hooks" added to facilitate communications with the existing structures.
Over time, these makeshift procedural structures also become institutionalized. Each of these new jobs and procedural structures evolves over time and takes on new characteristics which may never have been conceived of initially. Rarely, if ever, does anyone look to systematize these diverse tasks. There is a basic law of organizations which postulates that work expands to fill the available time.
Since these new tasks are rarely, if ever, added according to any plan and are in fact created to satisfy an immediate need, they have a tendency to contain redundant activities, overlap existing activities, and in some cases they may even be in conflict with existing activities. Moreover, because they were created in haste, they may be misplaced within the organization as well. That is to say, they may be performing tasks which may rightfully be the responsibility of some other functional area. Often, these new activities or tasks were created and placed within an area because it was easier to do so than to get the rightful area to do the work, or because the rightful area was too busy to do the work and the chosen area had free resources.
Each task should be examined in this light. Each form emanating from each business task should be examined with the understanding that no one may know where it originated or why. Many business forms and the tasks which either process or create them may be redundant, or worse unnecessary. The same reasoning holds true for business procedures.
Some Questions to Be Asked during Task Analysis
Task Modeling
Because of the nature of tasks as opposed to processes and because when analyzing tasks we are interested in how the task is accomplished, task models are usually produced in flowchart form.
The flowcharts should begin with the task trigger (a document receipt, a communication of some sort, or the movement of some material into the task area). Each manual, automated and mental step should be shown along with each decision point. Each calculation and each test should be clearly labeled and documented.
For each decision point, the decision question itself should be placed in the decision point symbol, each possible result of the decision (yes or no, present or absent, greater than, less than or equal) should be noted, and the steps which result from each possible result should be shown.
For clarity, the flow should begin in the center of the page, and each new decision action leg should be placed on a separate page as well. Any non-step information should be noted in the margins of the page along with form and reference notations as well. Calculations for steps requiring them should be noted in the margins as well.
Flowcharts should be annotated with the name of the task being depicted, the date the chart was produced, the analyst's name, and the name of the user source and the user reviewer. Each chart and each page of each chart should be numbered, and provisions should be made for chart revision information.
Data event modeling
Many if not all user task or activity models during the analysis phase must be developed inductively. That is their development must be guided by observation and data gathering rather than by a set of rules and guidelines which specify the logical order by which the components of the products are derived.
In all previous discussions the emphasis has been either on modeling some aspect of data, or modeling some aspect of process. There has, however, been a separation of data from process. Data event modeling unifies the two perspectives (data and process).
The end and most usable, and testable result of systems analysis is the identification of the processes of the firm and the data needed to support those processes. The data event models depict each user receipt of data, or each user use of data, specifies the actions the user must take upon receipt of that data or request for data and the data needed for processing. In addition the data event models depict the sequence of data retrieval, and the attributes of each entity occurrence needed both to retrieve the entity occurrence and that must be taken from the records of that entity occurrence once the entity occurrence is retrieved.
Deductive and Inductive Development
Although the development of each data event model (sometimes called process action diagrams, mini-specs, or user views) must be accomplished deductively for those events which are new to the firm, it should be accomplished inductively or empirically for those events which are already being recognized and handled by the firm.
Unlike all higher level products, these models must be complete, accurate and verifiable. They represent the final product of the design and it is from these models that procedural instructions (automated or otherwise) will be developed.
The documentation of each attribute and characteristic of each entity, as identified, must also include the identification of the individual elements of data which are expected to be part of the attribute. It is the data event model, and only the data event models which can accurately and completely identify what attributes, characteristics and elements are needed by the firm's user population to perform their tasks, because each of these models represents a logical view of a user task. These are models of the user's tasks as the business rules of the firm specify they have to be performed.
Data event models are used to describe the series of data actions initiated by a data event trigger from receipt through the point at which the processed data is finally recorded in the files of the firm. Obviously, some data events are more complex than others. However, concentration on enumerating data actions, and not the processing itself, can reduce the complexity and can clarify the data required for processing, and the effects of that processed on the files of the firm.
Data Actions
Data actions were briefly described in an earlier chapter. This chapter presents an amplified explanation and definition:
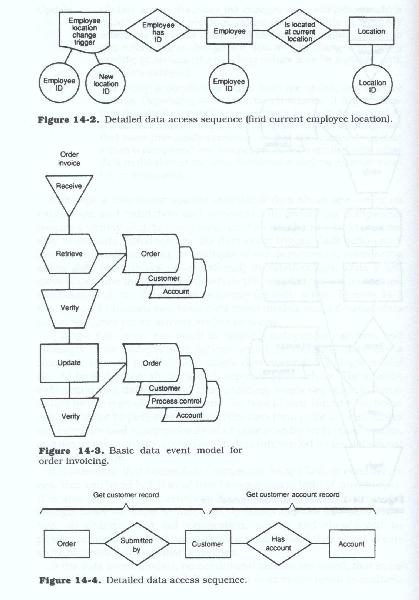
Receive: All data events begin with the receipt of some data. The receive action describes the data carrier or trigger that was received, how it was received or could be received.
Retrieve: The retrieve action describes the actions needed to obtain prerecorded items of data that are required to perform the verification and validation activities or to provide data needed from the reference files of the firm needed to complete new entity occurrence records. Each retrieve is initiated by a search. A search may be key or identifier (a characteristic) driven that must retrieve a single, specific entity occurrence or result in a failure condition, or it may be condition driven in which case it may retrieve multiple entity occurrences.
Search: The search is usually conditioned on one or more entity characteristics or attribute values although is some cases it may be existence conditioned (the next one in the file regardless of which one it is).
Archive: The recording of a previous entry for historical purposes, usually by recording the data element or set of related data elements (an attribute or characteristic) along with the dates or other indications of the time frames in which they were active. When data is archived, it is usually because only one set of values is true at a time but previous values are needed for research, or other management needs.
Add: Add a new entry, data element, characteristic or attribute to the files of the firm. Unless this adds a whole new entity member, the addition of a new occurrence of an attribute of an existing entity occurrence must be preceded by an archive action.
Update: Update action describes the changes or modifications which must be made to previous values of an attribute of an entity where the previous entry is of no historical value
(Update is also referred to as change, (the data may be changed in place), modify, or replace (the previous values may be replaced with new data values).
Verify: The verify action should follow both the update and retrieve actions. Depending upon what action it follows, it is a verification that the incoming data is correct and is to be applied to the correct records, usually by comparison with existing data that was previously retrieved, or that the change or update action is completed and has not produced a conflict with other data in the files of the firm. Verification may be manual, mental or automated.
Delete: A previous (archived) or current entry is no longer of interest and may be removed from the files of the firm.
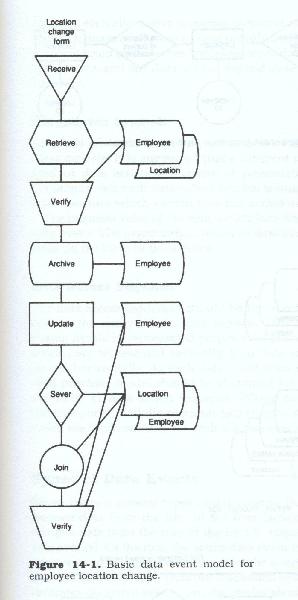
Although a data event usually introduces data about one entity, its verification and validation and sometimes its processing completion requires a variety of data about other entities which are related in some way to the data introduced by the data event trigger. Each action may involve multiple accesses to multiple entity occurrences, referencing either data (descriptive or operational) or relationships. Data event models describe the sequence in which the data actions are performed combined with the data access sequence for each action. Figures 14-1 through 14-4 illustrate two basic data event models and a detailed data action sequence for an activity within each one.
A single data event can result in multiple independent actions, and although those independent actions result in differing data being recorded, they all result from a single data event and a single model should be generated, showing each separate action chain. The specific data action and data retrieval and recording access sequence is determined by the type of data event and by the type of data introduced. Some actions cannot be performed without the data from prior actions, others can be performed independently of or concurrently with other actions others are mutually exclusive. All data introduced by the data event must be acted on.
It is axiomatic that before data changes can be applied, or even before new data can be added, it must first be examined in light of current data. It is also axiomatic that retrieval alone may not result in change. All change however, must be preceded by retrieval. Data that fails validation, or changes that fail verification, cannot and should not be processed further, at least not without one additional data event to correct deficiencies or augment omissions.
In the data event models, no conditional actions are noted, that is, no decision logic is incorporated. If the event results in or can result in multiple changes, each alternative sequence (action chain) is represented and all action chains are followed to final recording. The model depicts all data actions caused by the event, the sequence of data actions, the time frame of the event and any data or time dependencies which may exist within the event.
Data Action Symbols
A variety of symbols can be used to create the data action portions of these models. It is suggested that a different symbol be used for each kind of data action, for clarity of presentation and understanding. Accompanying each data action symbol should be a description of the business rules which govern how this action must be performed.
The business rules of the firm dictate how the firm must react to each data event. The organization reacts to data events and makes its decisions based upon those rules.
Data Access Sequence
The data access sequences should be represented using the same symbols as the entity relationship models. Data actions and data access chains should be represented perpendicular to each other. That is, if data actions are represented vertically then data accesses should be represented horizontally. As each data event from the timeline is modeled, each previous model should be examined for similarity of initiator or similarity of data action sequence. Where possible, data events with common, or potentially common data triggers should be combined where possible provided that the business rules for each are also similar or compatible.
Types of Data Events
There are two general types of data events, those that add, change or remove data from the files of the firm (active events), and those that retrieve data from the files of the firm in response to some query (passive events). Of the two, the active data event is the more inclusive. The passive event contains only receipt (of the query), retrieval, verification and validation actions. Thus our discussion of data event modeling will concentrate on active events but the reader should bear in mind that the same model development principles apply to passive events as well.
The general flow of each data event model should show:
The models should not indicate decision logic or processing. These are represented by the statements of business rules which govern each action in each event. The data activities are dependent on business requirements and company policy, and as such are less subject to change when represented in that form than standard processing representations. It is important to understand that company policies and procedures, legal, governmental and industrial regulations and standards also govern data handling. Time constraints, business priorities and normal lag between activities being performed also have a bearing on data capture and storage.
Most if not all data events occur or appear in a relatively random pattern and each one must be treated as a self contained unit, portraying only those actions which can be taken solely based upon the contents of the trigger event or from any associations or relationships which can be directly determined by or derived from it.
All data event models should be reviewed by all operational and other affected areas to ensure that the data that must be recorded from each data event is in fact recorded, that all history is archived and that data is not prematurely deleted.
It is important also to ensure that the operational areas responsible for the handling of each data event be clearly identified.
Relationship to Data Entity Time Lines
The timeline of each data entity is used to identify all of the events that can occur, or that can change what we know about the entity. Each (data) event in turn must be modeled and must document all of the data actions which must occur or should occur from the time the event happened, or the time the event trigger was received to the time its effects were fully recorded against each data entity to which it applied or that it affected.
Although each entity has its own set of data events, a single data event is not limited to a single entity. In many cases a data event may be identified as being on the time line for a number of entities. This is especially true of complex data events with complex triggers (such as an order). These complex data events usually are found toward the beginning of the entity time lines where new entity occurrences are identified and created or where major groups of attributes are identified and created.
All data entities that had to be retrieved or searched to verify the contents, complete the contents, fully record those contents, or to establish implicit or explicit relationships, are recorded in the same data event model.
No representations is made as to where in the files of the firm the data is to be recorded other than that it was applied to a specific entity, one or more attributes of an entity, or a relationship between entities.
Data Event Independence
The data event model portrays, or tries to portray, the effects and repercussions of the data event on the company and its knowledge of its environment. Each data event is analyzed independently and described both in model and in narrative form.
Each starts from a trigger event, the receipt of some document, intelligence or communication, or the occurrence of some event whose occurrence must be recorded and depicts the data actions which the business rules dictate must be followed to record that event and the data about it properly in the files of the firm.
Data events retain the context of the framework while depicting a more detailed view of data requirements and usage.
Data event analysis assumes that all data which affects the company enters via some data event and that all data events are connected to some trigger or data carrier. It also assumes that all requests for data from the files can be analyzed in the same manner, that is as a sequence of actions against data.
Data Event Sources
The task of the designer is to examine the sources of each data event and determine the contents of each data carrier in more detail. As stated previously, a single data event can originate from multiplesources, and thus can take multiple forms. The data event model allows for this, treats all sources conceptually, and models them conceptually, rather than physically. For each event the purpose served by the data being captured is documented, as is the information learned from it, and the reasons why the data and the data event is important (why the firm is interested in it). Data event models arebased upon assumptions of conceptual, general and expected content.
The models also depict the attributes and identifiers required to search and retrieve each entity, the attributes and identifiers acquired by the retrieval, and the attributes of each entityaffected by the event.
The data event model integrates action and data. Each action is modeled with the data required by or affected by it, depicted as a mini Entity-Relationship-attribute model. This mini entity-relationship-attribute model shows the entities, the relationships which must be used to associate the particular entities from which data is needed or to which data must be added or changed, and the attributes of both entities and relationships.
Data Event Triggers
Each event model starts with an initiator or trigger. The order receipt data event in our continuing illustration is just such a trigger. This highly complex data event is essentially a request for a product or series of products. It can be initiated from a customer, either orally or in writing, from a salesman, either orally or in writing. This new request for product (or service) arises (from the firm's perspective) spontaneously in that it was unknown, its arrival and content are unpredictable, and uncontrolled.
It may be assumed, for purposes of illustration, that any order has the following characteristics and general attributes:
Regardless of its characteristics or origination, it can be assumed that it is written or constructed from the viewpoint of the customer. The customer, the payer and/or the designee may or may not be known. The customer could be a person, institution, or company (or company unit). It may be requesting a product which may or may not be offered by, and it may or may not contain the correct description, price, etc. , of the product if it is the firm's. The firm may be able to agree to the specified terms, or not. In short, almost any part of the trigger (the order) is subject to scrutiny, examination and verification.
Although the aspects of each specific trigger variant are important, what is more important is that all the data that can possibly be gleaned from the conceptual (or composite)trigger be defined as globally as possible along with a description of the use of it to the firm and the effect it has on each of the data entities it is associated with. The model developers must also determine the associations (relationships) that can be formed between those data entities using this new data and determine how the firm can:
Data Event Trigger Contents
A list of the conceptual attributes (and data elements within each attribute) that can be expected on or with the trigger should be constructed. For each expected attribute or element the narrative must describe:
For instance, by looking at the order it can be determined who placed it. But there may be other information that has been provided that may also be of interest such as the title of the person or entity placing the order -Dr., Prof., Mgr., Director, Supervisor. There may be additional associative information such as "Professor on faculty of", or "Doctor is member of",etc. In most cases the location of the ordering entity can be expected. In the case of doctors, for instance, have practice specialty information may also be included on a letterhead or order blank. The implicit association of order and the ordering entity to one or more products of the firm product is included that may be of some interest to other areas of the firm, such as marketing.
Normally, the order will specify how much of what product or service the ordering entity is requesting, along with delivery information (when, where and how).
Each trigger, each order data event, then, provides product preference information, and if all orders from a customer are examined, the firm can construct a customer product interest profile, which may be of interest to marketing for future promotions.
Data Event Frame of Reference
For each data action the designer must determine the particular focalaspect, attribute, element of data or relationship for each entity. These references may be plural (in that multiple attributes may be needed) concurrentmutually exclusive or sequential, but all have to be identified. The conditions under which each search or retrieval may be performed must be determined, as should the data that is available as entity occurrence identifiers.
The must also determine the frame of reference of the data event. If, for example, the determination must be made as to whether or not the order is a duplicate, how can this be done if all that is availableis the information on the current order?What can be used to identify its potential and (potentially) preceding twin? How can it be determined from this order if the customer is already on file or if a new customer record must be constructed? Again, only the data which the customer has supplied on the order can be assumed to be available, along with any information already in the files of the firm. In each case, the answers to these and similar questions should be noted on the data event models alongside the appropriate data action or data access model component.
For each entity in each data access chain retrieval conditions, identifier availability, update (add, change, delete) requirements must be determined, archival requirements must be determined (versus what changes can be made in place) by attribute. Data recording requirements must be determined. It is probably also useful to record at this point, for later verification, why these things are being done or why the designers felt they should be done. This is done so that in the later design verification process the interested parties can be questioned as to whether it really is important that the data item be archived or whether it can be discarded (overwritten).
The data event models to categorize the various groups of data by attribute or characteristic groupings (i.e. address data, demographic data, payroll data, ship to data, bill to data, invoice data, acquisition data, location data). During the modeling process, it is very important to remember the following two points:
It must be assumed that each data action (the action taken within the data event and against the data entity) will result in multiple actions taken against each entity, that multiple separate retrievals may be made each against different attributes (i.e. employee address data, employee benefits data and employee salary data).
Sequential actions, (i.e. payment data cannot be retrieved until the invoice to which the payment is to be applied has been retrieved, and the invoice cannot be retrieved until the proper order has been identified), then the attributes should be placed vertically beneath the entity symbol, indicating this dependency. Concurrent actions(attributed that can be retrieved in any order) should be represented horizontally beneath the entity symbol.
Aside from the above, there should be no time references in the model other than the implicit ones of start and finish (receipt and recording). The data event may call for multiple retrievals of the same or differentoccurrences of any given entity. However, the event is modeled as if it occurred to the one entity.
Sequential Data Access
The above discussion refers to the event from the timeline of one entity. In our discussion referenced data actions which required data from multiple entity types, and we modeled them according to whether they had to be acted on in sequence or concurrently. This sequential retrieval of data is required because while some data actions could be accomplished directly and with only the data from the trigger, others required additional data to be added to the trigger data to accomplish the actions. Those additional data elements had to be obtained through an action against some other (and indirectly referenced) prerecorded entity. To illustrate, a customer's salesman's phone number and address can not be determined until the customer's records have been retrieved and examined and it can be determined who the customer's salesman is. Then that salesman's records can be examined to determine his phone number and address.
A relationship has been established between two entities when it is determined that this kind of conditional data access exists. On the model this relationship can be portrayed by inserting a diamond symbol between the entities and noting the data elements first from the trigger and then from the originating entity (the full path of data elements in other words) which are necessary to uniquely identify the conditions of access and identification to the target entity. Any qualifying data that is necessary to ensure access to the proper occurrence of the target entity should also be noted as attributes of the relationship or the participating entities.
Again, the time frame of the data event does not extend beyond the recording of the data event in the files of the firm. Later processing or reporting is important, but each event is only concerned with the determination of what data must be recorded and where that data is to be recorded such that it can be acted upon or recalled later.
The worst possible case is should always be assumed in terms of event and data trigger complexity. Maximum trigger data content is also assumed. The designers should not focus on one particular trigger, but on all possible and potential triggers of the same data event.
All data is assumed to be recorded in the files of the firm and against some entity within the files of the firm. Thus, all retrieval is assumed to be from the files of the firm and from some entity as well.
Data Event Assumptions
One final item: for data event modeling to be fully effective, it must be assumed that:
This implies also that in modeling any data event, designers cannot rely on data being present in the files of the firm. Thus a retrieval must be initiated to ascertain whether the data that is expected to be there, really is there, whether this data event is a duplicate of another, or more importantly, whether when changing, adding or deleting data, the assumed current values are what the firm thinks they are. No blind actions should be allowed.
These two conditions dictate that as something happens, it must be recorded. If one company unit records an event which another or others must act on, it must record that event such that those later units can identify it with the data available when their data events occur.
A refinement of this modeling technique is to make a distinction at the time data is update or added, between data attribute modification and relational modification. Two additional data actions which can accomplish this might be join (add a relationship) and sever (delete a relationship). Potentially there is a rejoin action which is a change operation. This separation of data modification actions from relationship modification actions provides a clear presentation of the sequence of data actions and the effects of the data event in the files of the firm. These actions are not to represent relational path access (in the technical sense) but rather data actions which are specifically against relationship data and which could just as easily be implemented by add an entry to a cross reference list or remove an entry from a cross reference list.
Separation of Data Event Types
The separation of data actions into those affecting data and those affecting relationships serves two purposes - one immediate and one long-range. The immediate purpose is to clarify and further refine the data event model. This also highlights the relationships which are established or affected by the data event
The long range purpose is that it assists the implementation teams by focusing their attention on the relationship maintenance tasks. These task might otherwise slip by unnoticed. The more relationship processing a data event entails the more important that data event is to the files of the firm and thus the more attention that must be allotted to its design.
Each data event must be treated in a generalized, logical or conceptual manner. That is, as a composite of all possible variations of all possible actions which can be taken for that data trigger. This is especially important if we stop to consider that each entity which can be acted upon is conceptual or a composite of a whole family of members.
In our example, the order originating from an individual for a single product may be treated differently and may link differently from an order from a purchasing department of a chain of stores for multiple products to be shipped to each of its individual stores.
Data event modeling requires a detailed knowledge and understanding of all of the variations of all of the entities under consideration. Each data event must be viewed in light of each variant of the trigger and against each variant of each entity which that data event can possibly affect. Each data event and each entity must be examined from two aspects:
A Professional's Guide to Systems Analysis, Second Edition
Written by Martin E. Modell
Copyright © 2007 Martin E. Modell
All rights reserved. Printed in the United States of America. Except as permitted under United States Copyright Act of 1976, no part of this publication may be reproduced or distributed in any form or by any means, or stored in a data base or retrieval system, without the prior written permission of the author.