Data Entity Time Lines
A system design is not developed in a vacuum, nor is it developed from thin air. New systems are designed or, as we have shown previously, redesigned to allow the firm to implement changes which could not be made in the existing system. Each system design team begins with the results of the system analysis phases. This analysis documentation details the existing procedural environment from a variety of levels and from a variety of perspectives. It also documents the existing data files, the sources of the data in those files, and the uses to which that data is put within the specific functional areas for whom the system is being developed, and within the firm as a whole.
In addition to the analysis documentation the system design team also has the results of the examination and study phase which documents where changes need to be made, where new procedures need to be added and where old procedures need to be deleted. This material by itself however is not sufficient to design a new system.
Rarely if ever does the new system duplicate the old system, either procedurally, in scope, or in focus. Because of the various pressures which are exerted on the design process to add new capability,
increase flexibility, and to integrate more and more processes into a single system the design teams must also develop new ways of arranging and organizing the processes to achieve these desired goals.
However every new system must also fit and operate within an surrounding systems environment which may remain largely unchanged. The new system design incorporates the required business changes and also allows the designers to take advantage of the opportunity to make other, less obvious, but equally advantageous changes for the future. That is to incorporate features in the new system which can be implemented because other changes are being made at the same time. These are opportunity changes. Opportunity changes are those which can only be made because other changes are being made at the same time.
Almost every new system is thus distinctly different from the existing system it replaces. These differences are over and above the actual procedural changes at the task level. The differences show up most clearly in the changes in focus designed into the new systems, and in the changes in the work flows, or procedural flow of the new system. In other words, the changes are not only made to the tasks being performed and how they are to be performed, but also to the order or sequence in which these tasks are to be performed. The most visible changes however are in the new tasks which are added to the system, and in many cases the change to focus of these systems. We can illustrate these types of changes with two relatively common examples.
Administrative System Changes
As administrative systems become more integrated one of the first to change are those which service the personnel areas or as they are now called human resources. The many individual processing systems which were developed to support this function are slowly being consolidated and integrated into a single system. In order to perform this consolidation, system designers have shifted from a process orientation to a data orientation. That is they have stopped viewing the individual systems such as payroll processing, personnel record processing, benefits processing, and have instead begun to look at the individual procedures as components of a new system which has the employee as its focus rather than specific processing as its focus. This has allowed system designers to redesign and rearrange the procedures in a manner which is both more efficient and more flexible and in many ways more natural. It has also allowed the designers to eliminate redundant data collection and processing and redundant files of employee data.
Operational System Changes Operational systems have shifted from a focus on specific processes such as inventory, purchasing, receiving and quality assurance to a product focus which results in more global systems such as materials management systems. Other operational systems have shifted from order entry, credit approval and order processing, to a more global customer service approach.
These consolidation of systems have also allowed the systems to approximate in scope the corporate functions which they were designed to service. They are more global in nature, more all-encompassing and because of that, more complex.
In order to achieve this consolidation of smaller systems into larger more integrated systems, designers have looked for commonality between these systems as a means of tying them together. In most cases what these systems have in common are the entities which they service or around which their processing revolves. These entities can provide the system designers with a focus and a framework around which they can redesign the system.
From the system and procedural perspectives these entities are represented by data which the systems have stored in their files. This data represents both the descriptions of these entities and a record of the actions taken by them which affects the firm, or by the firm which affects them.
Administrative systems usually revolve around a single entity, such as the employee or the ledgers (accounts). Operational systems on the other hand may focus on three or four entities at a time such as the customer, product, order and warehouse entities.
The Framework as a system outline
System frameworks are developed for a variety of reasons. They act as road maps for the design team and at the same time they help to establish the scope and set the constraints of the system. The most important reason for the frameworks are to provide the design team with a focus for their activities. Just as an outline guides the writer in his or her chores, so to the framework guides the design team in its tasks. The various frameworks provide the design team with methods of organizing their activities and the subsequent design so that the final product is both complete and coherent. In other words, it helps the design team to make sense of and provide order, or to systematize, an otherwise disorderly environment.
The design team must know what the new system is to accomplish, must decide how it is to accomplish it, and most importantly it must know when the design is complete. Frameworks can provide answers and guidance in all of these areas. Frameworks of a different kind can assist the designers in identifying and organizing the components of the system design.
The preceding section discussed the use of data as a framework and presented an entity-based approach to developing a data model. The entities and their relationships with each other could be used as a framework around which to develop a data model of the system. This chapter uses the concept of the entity, not as a way of organizing data, but as a way of identifying and organizing procedures. To do so we will introduce the concept of the data entity time line. The development of data entity time lines help the designer organize the system procedures in a rough chronological order and to categorize them in ways which are meaningful to the system's users.
The Data Entity Time Line
The concept of the data entity time line is based upon two premises:
These events for each entity can be identified and they can be arranged in a manner such that the data gathering and internal processing portions of the system can be designed around them.
Business systems are designed to provide order to the myriad of individual tasks which have been developed to gather, process and disseminate business data. One way in which many businesses have arranged these tasks is to assign responsibility for them to various business areas, or functions. This assignment process is usually based upon some commonality between the tasks. That is, tasks which involve inventory are assigned to the materials management function, tasks which involve employees are assigned to human resource functions, and so on. As the number of tasks increases they are further aggregated into smaller groups and assigned to functional areas, such as payroll, personnel record keeping, benefits, or recruiting.
The Processing Environment
The tasks themselves however occur on a random basis, and are triggered when either new data about an existing entity comes to the attention of the firm, a new entity comes to the attention of the firm, or the firm loses interest in an existing entity. Other tasks are triggered because some set of conditions or in some cases the mere passage of time has caused the firm itself to make some change in the data it records about an entity. These company initiated changes may or may not be communicated either to the entity itself or to the owner of the entity. By and large the firm has little control over the timing governing when tasks are initiated or triggered.
If we divide the tasks into those the company initiates and those initiated by entities outside of the firm, we would see that roughly half come from outside the firm, and that the company has no control over when they are initiated. Of those initiated by the firm itself, may of these are in response to actions which themselves occur in a random pattern, and are relatively unpredictable. If we combine the random nature of the events with the fact that many of these random events contribute pieces of data to complex tasks, can see that developing complete processes, much less, a complete system can be very difficult unless we establish some constraints over how and when the data generated by these random events will be processed.
Once an event happens the firm can assume some control over it but only up to a point. That point is usually reached when the processing requires data which has not yet been generated or reaches a point when it has to wait for other tasks to complete. This interaction of tasks and the development of a framework to coordinate and organize them will be the topic of the next chapter on the functional or processing framework.
Given the above processing environment, the effectiveness of a system is dependent upon the ability of the design team to develop an effective set of frameworks within which to develop the detail processing procedures.
The successful development of the system work flow or the sequence in which the procedural tasks are to be performed is dependent in a large part on correctly identifying the actual procedures to be performed. The development of these procedures is in turn dependent upon identifying the events or conditions which trigger the tasks and actions. The development of a data entity time line is a method for assisting the design team to identify those events and triggers, and their associated procedures in an organized fashion.
Time Line View
The data entity time line views the individual data entities as the reason for most corporate activity. That is, corporate activity focuses on the collection of data about each entity as the reason for the processing rather than the processing being the determinant for gathering data about the entities. corporate record keeping with respect to business transactions is also largely organized by entity.
System design is concerned with data. More specifically it is concerned with the collection and storage of data, the processing of that data and the dissemination of that data. Although we are concerned with all aspects of data, from this perspective it is the acquisition of data which is our primary concern. If the appropriate data is collected, and if that data is filed in the proper manner, in properly structured files, those files can provide for and support any business function, be it process or reporting.
By extension, any organization's business systems processing activities can be divided into two parts, input (data collection) and output (data dissemination). Data entity time line development defines the data from the input side. Specifically, it attempts to define the type of data which the firm needs to collect and the sources (events or triggers) of that data. On an entity by entity basis this framework development technique identifies the individual forms and sources of the data which the firm must transform from its original form to its final stored form. In effect this is an application of data source and use analysis techniques to the process of system design.
Transactions and Data Events
In order to discuss the data entity time line framework we must introduce and discuss a few concepts. These are transactions and data events.
Definition
A transaction is the performance of a specific piece of business. Transactions are the conduct of business and all business involves the conduct of transactions. A transaction thus may involve many different tasks and activities, and in fact may involve whole processes.
The term transaction is not a very clear one, and although it is used more frequently than almost any other in the business processing world there is little agreement as to just what a transaction really is. However since transactions are at the heart of the business, the system design must depict them in some manner. To develop the data entity time line framework we will use the term data event rather than transaction.
Definition
A data event as some act, occurrence, set of conditions, or passage of time which causes the firm to generate or receive data which either changes the meaning, values or contents of previously stored data files, or which adds to that store of data.
A data event is some occurrence of interest to the firm that the firm needs to remember or that generates data which the firm wishes to use to add to, modify, or deletion from, the contents of the company files. It may be caused by a procedural processing activity of the firm, by the passage of time, by the action of some entity of interest to the firm which changes some attribute of the entity, or another entity of interest to the firm. A data event may result in the addition, modification or deletion of a relationship between two or more entities.
Once a data event occurs, it precipitates a series of specific and prespecified actions which result in the changing of data within the firm's files. These actions are performed to edit, validate, this new data and either place in the company files, or to use it to modify existing data. Thus we can view business systems as the effects of a series of related data events.
Development of the data entity time line
Each entity of interest to the firm can be described in terms of its life line or time line. This line begins when the firm first recognizes the entity and ends when the firm ceases to be interested in the entity. Although the start of this line is usually a relatively fixed point in time, and can be identified with a specific event such as receipt of the order or the identification of an employee candidate, the end of the line is usually much less defined. In many cases the firm may not have identified a specific event where interest ceases and the file for some of the entities may continue indefinitely. Between beginning and end, start and finish, other events happen randomly.
These time lines correspond roughly to the individual business work flows since most processing systems are organized around the collection and processing of data for a specific entity and that data collection is conducted in a rough chronological manner. That is to say, one event triggers another which triggers still another. What makes processing difficult is that these events usually alternate from internal to external origination.
A sequence of these alternating events becomes a process. The completed system is the interconnection of these individual entity processing work flows.
The entities themselves are dynamic. The information about them is constantly changing. These changes occur randomly. Changes may originate within the firm as it does something to the entity or it may originate outside the firm when the entity itself or some other entity does something which changes some aspect of the entity.
Entities of interest to the firm
We have used the phrase "entities of interest to the firm" consistently. In order to understand the time line concept we have to further define what we mean by entities of interest to the firm. Obviously, not all entities are of interest to the firm. The firm is only interested in those entities with which it interacts, or which it uses in the course of its business transactions. Further, the firm is only interested in those instances of those entities to which it is specifically related. In other words the firm is interested in vendors but only those vendors from whom the firm buys items, would like to buy items, or has bought items in the past. In some cases the firm may also interested in vendors from whom the firm would like to avoid ever buying items.
To continue the example, for each vendor of interest to the firm, there are many things which could be known but there is a limited subset of those things (attributes) which the firm actually wants to know. This subset of "want to know" things, may be further limited by what the firm actually needs to know. The basic design for the new system must include the "need to know" items, should include the "want to know" items, and could include as many of the "would like to know" items as resources permit.
There are many things which can happen to the vendor, which change it, however the firm is only interested in those changes which relate to its interaction with that vendor.
Even the list of things which are of interest to the firm is a rather lengthy one. The designer could attempt to determine all the things about the vendor (or any entity) that the firm wishes to know, and the would probably be a long list of attributes or data items with no particular order or arrangement. This is in fact the way most system designers attempt to accomplish this task. A simpler way is to ask the following set of questions:
Producing a Data Entity Time Line
For each entity of interest (not entity instance) we start with a straight line to represent the entity time line. On this line we indicate each of the things that can happen which cause what we know about it to change, or what can change it intrinsically.
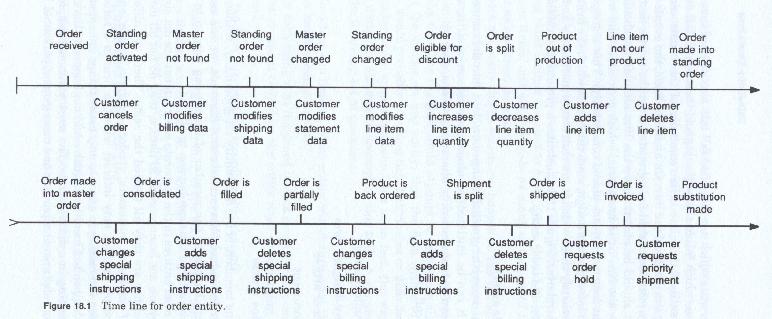
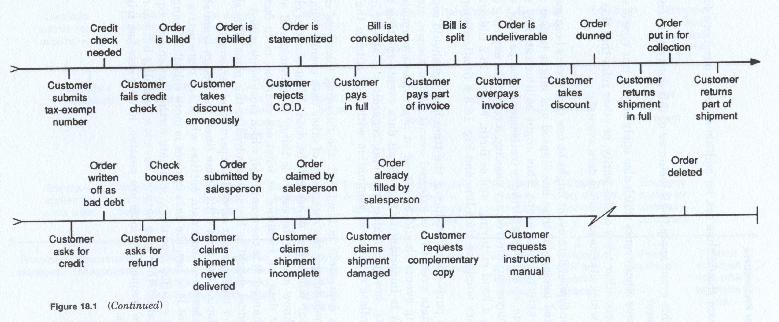
The data events which are identified fall into a number of time categories. Those which fall at the beginning of the entity's time line and those which fall at the end of the entities time line. The remainder of the events can be placed along the middle of the line. On an initial basis, the events which are company initiated should be segregated from the events which are not company initiated. One set should be placed above the line and one set should be placed below the line (it is immaterial which goes above and which goes below as long as they are placed consistently). This segregation will help the later system design, since those events which the firm initiates are obviously those which it can restructure most easily, and which it has the most control over. Figure 18-1 illustrates a preliminary version of a time line for the order entity.
What is a Data Event
A data event is anything which brings new data into the company's awareness. The data event can be initiated for almost any reason, and the data itself can be transmitted by almost any means, such as:
If we treat the members of the data entity set generically, without regard to their individual idiosyncracies, or differences, we can expect that what can happen to one member of the set can happen to any member of the set and thus can happen to all.
However most entities in the corporate environment are not simple entities. That is they are not homogeneous in nature, they do not all look, or act the same, nor are they all treated the same. There are different categories of employees, customers, vendors, products, orders, etc. The people entities may interact with the firm in a series of roles. A person interacting in one role may cause things to happen, or have things happen to it, which could not happen to the same person interacting in a different role. The most common examples of these types of roles, are sales persons and management personnel.
The design team should thus ask an additional set of questions for each event:
Another type of data event might be one which occurs because some prespecified passage of time has elapsed which might trigger an internal or external data event. This might be illustrated by a loan coming due, an employee birthday (retirement date) passing, a company employment anniversary passing, a copyright expires or is due to expire, a bond matures, etc. Figure 18-2 illustrates a preliminary employee time line.

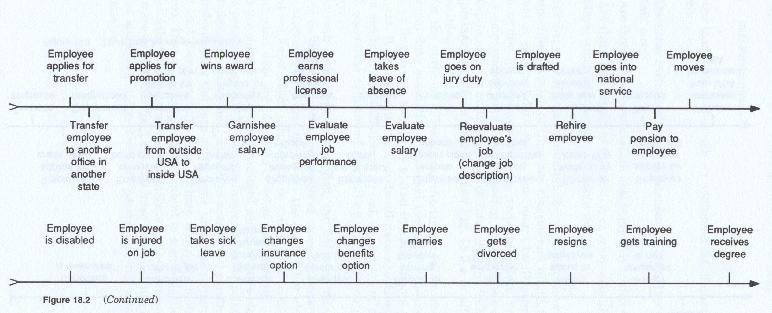
Figure 18-3 illustrates a finalized employee time line
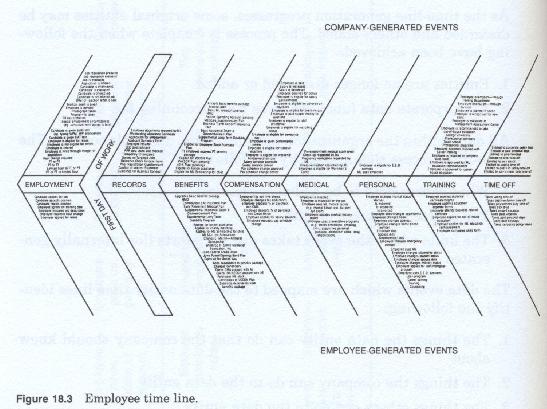
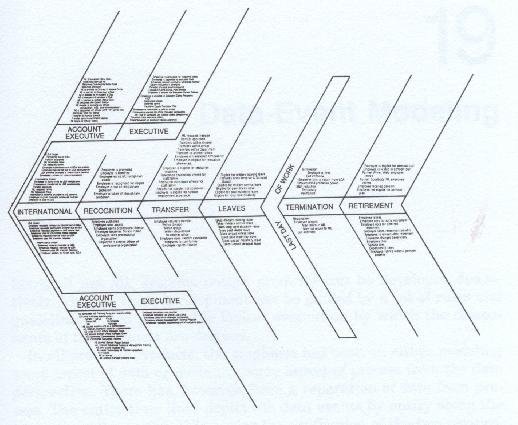
For the purposes of producing the time line, we should separate internal data events from external events. Where known, starting and ending events should be placed in approximate chronological context.
It is important to include all data events relating to the data entity, however major or trivial, regardless of size of impact, and regardless of point of origination within or outside the company.
As each data event is identified, the question "What else can happen?" "Where else do we get that data?" "What else can change what we know about this person or thing?" can be asked to help trigger the awareness of other data events.
It is immaterial at this point as to what data is identified or what is changed, or in fact how it is changed. It is the event itself which must be identified.
User area personnel should be heavily involved at this point. This should include the user management, as well as operational personnel.
In developing the data entity time lines the design team should find that there are some data entities which are more active than others. That is to say, the data content is more volatile. Changes to these data entities produce or instigate further actions or requests for more data. Other data entities have low volatility but are referenced more frequently. Some are passive, having acted as a trigger themselves.
Changes in the Entity Model
As the time line generation progresses, some original entities may be discarded, and others added. The process is complete when:
All data within the organization has some ultimate, definable source or sources.
The time line process should identify:
The data events which are mapped to the data entity time lines identify:
In some cases, it is not only the things which directly affect the company, but those in which it might be interested which are entered on the time lines.
Sources of Time Line Content
During the process of developing the time lines, the business and personal experiences of the analysts and user come into play. It can and should become somewhat of a "blue-sky" effort or a "brainstorming" effort. The more data events which can be identified, the more effective the process. Any data event which can, does, or might happen, or which the participants would like to see happen, is added to the time lines. Later design analysis may discard some and add others. At this point, it is immaterial to know whether it happens, if it does happen, how it happens, or how we can obtain the data implicit in the data event. It is a conceptual process, far removed from implementation considerations. User knowledge of the entity under analysis, its characteristics, traits, habits, etc., are extremely critical at this point.
Using this concept, the design team can focus on identifying the sources of data for the company. All these activities or events on the life of the entity which cause change in company data, whether manual or automated, must be identified at this point.
Once the design team is relatively confident that the data entity time lines are complete, they should review each time line individually. Each data event should be annotated for the following information:
Why use a time lines
There are two questions which always plague any design team. First, have we covered everything we should, and second, have we covered too much.
These questions arise from the complexity of the systems and in difficulty in determining the scope and structure of the systems. The time lines direct the focus of the design team on business events and away from processing. Business events rarely change, just as the entities of the business rarely change. The processing can and will change. In fact the primary reason for new systems designs is that systems can't change fast enough.
Times lines look at the actions of entities, by entities and against entities. It looks at what they do, rather than how they do it. The process of system design is an organizing or more specifically a classification effort. The difficulty is to determine what to organize around. Frameworks provide that organization. Entity time lines are organized are around entity activity life cycles. The next chapter will discuss the mapping of the individual actions, or data events, and as we shall see these data event maps provide the mechanism for integrating process and data.
Data Directed Systems Design - A Professional's Guide
Written by Martin E. Modell
Copyright © 2007 Martin E. Modell
All rights reserved. Printed in the United States of America. Except as permitted under United States Copyright Act of 1976, no part of this publication may be reproduced or distributed in any form or by any means, or stored in a data base or retrieval system, without the prior written permission of the author.