The Data Framework
One of the major factors which has affected the process of system design is the gradual movement from the private data file environment to the common data resource environment and its impact on the resulting system design products. This movement resulted from the pressures to introduce more and more shared data into the business systems being developed, to introduce more and more management control and standardization procedures, to provide greater levels of business management information, and to provide greater levels of management access to information.
To respond to these pressures, different types of systems frameworks have been developed. One of these frameworks is the data framework which seeks to integrate, standardize and provide greater access to firm data in more flexible ways.
There are two perspectives of data - each of which affects the design process in different ways. Neither of these perspectives is concerned with whether these files are manually maintained or automated. They are however concerned with the scope and contents of those files, with the accessibility to the data contained within the files, and with the completeness, timeliness and accuracy of the file data content.
Private file perspective
The first is the business function perspective in which the data resource of an organization is viewed as the aggregate of all the private or operational data files which have been, and continue to be, collected and maintained as a result of normal business processing. The contents of these files are continually referenced in support of the specific business activities for which they were created, and the data within is extracted for reporting, auditing, accounting and further processing by other activity units within the business.
Under this view the data in the files are an adjunct of the business processing and it is the processing which determines the data rather than the data which determines the processing.
This perspective also views the data as belonging to the operational area which manages the processing and it is treated as any other purely operational resource. This perspective is most common in the vertically oriented operational areas of the firm, and was the perspective which pervaded the systems designed in those firms in the expansion stage of growth.
The timeliness of the file content depended upon the user's processing cycle, be it daily, weekly, monthly or any combination thereof. The result of these two factors, user area specific design and user area dependent processing cycles, was that rarely, if ever, were the contents of any two files from different user areas synchronized even if they contained data on the same subjects. Rarely, if ever could the contents and format of one user area's files be used by a different user area, although selected data could be extracted, reformatted and copied for another user's use.
These user specific private files represented the data from documents and forms usually designed specifically by and for the user's processing and reference needs, processed by the user according to the user's procedures and in accordance with the user's own standards. It was thus highly personal and personalized data.
Rarely were these user files used, usable, or in fact desired, by other user areas. Each user area was only interested in the data necessary to support its specific processing needs.
The records in these user area files were invariably maintained in a fixed sequence which was usually determined by the user processing needs.
The user area then, owned the files, and was responsible for the maintenance and the accuracy of the data therein.
Another characteristic of user area files was the timeliness or cyclic nature of the data within these user area files. The files were created and maintained within the user processing cycle. That is to say, the data was as current as the user needed it to be and its timeliness was based upon the user's own needs.
Common data resource perspective
The second perspective of data is the business resource perspective. This perspective usually supported more by middle and senior management functions than by operational management functions, is one in which data is viewed as a common resource. This view is growing increasingly more prevalent as firms move from the early stages of processing growth to the later stages, as they grow increasingly aware of the need for more integrated business information, as they grow increasingly aware of the need for more stringent business and processing controls and as they attempt to introduce greater levels of integration into their processing systems.
This is the central file room approach to data, in which the central file staff sets standards for the acquisition, maintenance and use of the central data files, and control both its modification and access to it.
This perspective seeks to maintain commonality of form and definition. It sets standards in terms of minimum level of content validation and verification.
The common data resource perspective views data as a river flowing thorough each user area, nourishing all who live on its banks, as opposed to the private file perspective which views data as arising from individual wells which may used as their owners see fit.
The common data resource perspective is not applied to all data, there will always be a need for private files. It does distinguish between commonly used and commonly referenced data, where consistency must be maintained, and private file data where only the data owner is concerned with its contents and accuracy.
The common resource perspective, by treating the data as a sharable resource containing commonly used data and information, supports the integration of systems, by maintaining common data in a consistent and readily accessible form which in turn supports management's increasing need for information. When the common data resource approach is used as an integration mechanism between processing systems, and as the level of integration increases, more and more data within the common data resource (or database as it is called) can be captured and maintained by those units within the organization where it logically and operationally originates, and can be used in common by all units of the organization who need it. This commonality of data use can reduce the redundancy of processing which occurs when multiple user areas must gather, edit and validate the same data.
To paraphrase a well known philosopher: "From each according to its function, to each according to its needs". This philosophy underlies the common data resource or central data base concept.
The use of the common data resource approach as an integrating and centralizing mechanism has been likened to that of taking all of the files found in people's desks and private file cabinets, and trying to use them to create a central filing system, while at the same time removing redundant information, making sure all of the file contents were correct and trying to impose a common cataloging and indexing system on all of them.
To use this common data resource perspective as an integrating mechanism, all processing tasks for all functions which are expected to use the common data resource must be examined from both a data orientation and a process orientation.
Private file design considerations
In a private file environment the design activities focus on an individual user area's processing activities. The existing processes are analyzed and the new or modified user processing specifications are established. Processing sequences are established and work flows developed to support the interconnected processing sequences.
Files are developed to hold data between processes. There is no attempt to retain any more data than is needed by the particular processing unit, and the data that is retained does not have to conform to any rules other than that of the particular user. Since the emphasis of the design is on the processing, and since data is considered to be determined by that processing, little thought need be given to either data planning, data uniformity or data consistency.
Each processing area is concerned with accepting data from other processing areas and from outside the firm, processing that data and passing that processed data on to others. The files they construct facilitate these processing activities but are not a product in and of themselves.
Little, if any, consideration is given to the needs of other processing areas for the same data, or for data which might support the processing requirements outside the user area. In fact the user area is treated as if it is a self contained unit. The user's processing requirements determine the data collection forms, and the user's control and information needs determine the reporting forms. The user is free to develop his own data filing schemes, his own data coding schemes, to determine what data will and will not be retained, and for how long that data will be retained.
Since the user area both owns and controls its data files there is no need for special access controls, data security controls, or maintenance or update controls. No one other than the user area personnel have access to the files and they know at all times what the status of the files are.
Data files are designed to contain the data source documents, intermediate data collection documents, work in process data, and archival data. The data in these files is then used to create the reports for the user. These files are established and designed primarily to store data for use by the user area, and then only to support that user's own reference needs or to hold data within, and between, the user's specific business processing cycles.
Common data resource design considerations
The design considerations for a common data resource environment differ markedly from the private file environment. The same types of files exist, and they must support the same types of processing and informational needs of the same user areas. The critical differences lie in the following areas:
The development of the data framework for a system design must address each of these critical areas and provide for their resolution. Many of these tasks and considerations are addressed on a formal basis for the first time when a common data resource is developed. For others, the designer's task is to resolve the different methods chosen by the separate user specific areas as they address these issues when designing their private files.
Many design projects attempt to move all of the private files into a common data resource. This fails to recognize that some data files should legitimately remain private, or user specific. The framework which must be developed during the system design project must distinguish between common and private data, design data files for both, and populate each type of file with the data appropriate to it.
The movement from private files to common data files is a natural one and this movement follows the movement of processing systems on the growth stage curves.
The need for a common data resource
In order to achieve effective levels of processing integration, and data centralization, organizations need to record all necessary data for both short and long-term use , process and store it in a common set of files, in a universally agreeable manner and make it available for common use. The systematic, short-term, accurate recording of data is basic to the successful daily operation of the individual operational areas of the firm. The systematic long-term accurate recording of data is basic to the long-term survival of the organization. Both short and long term data provide a permanent record of the corporation's activities, this recording of data sustains the auditing, statistical, forecasting, and control functions.
As in our desk drawer data storage example above, usually, the firm's data is stored in a decentralized manner, reflecting the operational departmentalization of the organization. Payroll records, for instance, are normally stored in the payroll or accounting department, personnel records in the personnel department, shipping records in the shipping department, and original orders and customer purchase orders in the customer service department.
Because of differing processing and reference needs, many original records are duplicated and these duplicates are stored in more than one operational area. Copies of purchase orders, for example might be kept in purchasing, inventory, receiving, quality control, accounting, and in the originating department itself. As each area performs its part of the processing, the base data is modified.
Rarely, if ever, are all copies of the base data changed in unison; thus, to gain a complete picture of a particular order transaction, one must look into the files of each area that had access to, or processed, the original purchase order or a copy of it in some way.
As a result (and to the detriment of the firm), the data in each processing area is incomplete or, worse, inaccurate. At best, it is validity and accuracy is suspect. In any case, only those areas that have copies can use the data and then usually only their part of it. Thus, the view management has of the data it receives is biased toward the operational area from which it was obtained. That is to say, only the data germane to a given area can be expected from that area.
Data versus information
Data files can be divided into several types:
We can categorize data files into two other groups:
Data are facts. Data items or groups of data items are usually descriptors in reference files, as opposed to information items which are more commonly found in processing files.
Information results from data which has been processed. Information files, as opposed to data files, represent "frozen processing" and may reflect the judgement and opinion of the processor.
Within the data framework, data should be clearly separated from information and clearly labeled as such. Both data and information enter the organization on a continual basis, arriving randomly. The variety of their sources means that at upon entry, they usually do not conform to the firm's rules for accuracy or completeness. This requires that the firm edit, validate and verify these items before they are recorded in the firm's files, and before they are used for business processing or business decision making.
Both data and information are collected by the firm and used to represent the real world things with which it interacts as part of its normal operations. Data and information describe the intangible things within the firm. The ebbs and flows of data and information within the firm's files represent the business transactions which are a part of everyday business life. The business files are highly dynamic and reflect the constant changes in the business environment. The business files also reflect the status of the various processing operations which are performed on an on-going basis. As with the processing procedures of the firm the firm's data and information files are subject to changes. Some of these changes can be made easily, some are more difficult to make. Over time, the impact of constant change and the need to store new data and information is one of the driving forces behind a new systems design.
It is debatable as to whether processing changes determine data file changes, or whether data file changes determine processing changes. In all likelihood they are codeterminant. Thus the design of the data and information files must be developed concurrently with the design of the processing procedures thus the needs of each will be reflected in the other.
Data framework considerations
As with procedural design, file design must occur within a framework which ties the separate private data and common data resource files of all types together into a cohesive unit, such that they all reflect the same perspective. This framework must include:
Data framework development
Data is one of the raw materials of any business. When deprived of data the organization will wither. Data which has been filed but which cannot be retrieved is as useless as no data at all. Data which can be retrieved but is outdated, incorrect, or improperly defined, is similarly useless.
Most organizations today are so dependent upon their data and the ability to retrieve and process that data, that if that data were destroyed or rendered inaccessible, the organization would collapse; some would cease to function.
The development of a data framework during the system design process will eliminate the problems, and address the issues and considerations outlined above.
The design of a data framework may start at the enterprise, senior management, strategic, or operational level. It should start one level higher than that of the system being designed. The primary component of the data framework are a set of data models. These data models must reflect business and operational context. The data model should describe what the data files will contain and how they are related to each other. These models or supplementary models should depict the sources of each data item and the uses to which it will be put.
Most organizations generate and use massive amounts of information, both formally and informally. Massive, not necessarily in terms of volume, although there are those whose volumes are exceptionally high, but massive in terms of the variety and complexity of their data.
The data model organizes, categorizes and classifies the data requirements of the firm into groupings which allow for logical placement of and access to the individual data items. Most data items are used to describe:
Because of these uses of data, most data models organize and aggregate data around the people and things the data items describe. These people and things are called entities. Each data file whether a private file or a common data resource file is composed of groupings of data items which describe these people and things (and places). The rules which determine the content and relationships between the groupings of data items within each file, and the rules which determine relationships between files represent the data or information model of the organization. That is to say, all business processing procedures can be expressed in terms of:
Most business procedural processing at the operational level is devoted to the acquisition, editing, verification and validation of data. The redesign of these procedures are dependent in a large part upon a correct assessment of the firm's current and future data and information needs. These procedures are also dependent upon the filing system used and the format and layout of the files and records. In other words, part of each procedure is determined by the data and how it must be processed, and part of each procedure is determined by where the data is and how it must be retrieved and subsequently store after processing.
An individual business procedure is rarely of long duration between initiation and completion. The actual duration is dependent upon both the amount of data in the transaction initiator, the actions to be taken on the data contained in that initiator and the ease with which the procedure can retrieve the necessary reference, verification and validation data to support the procedure.
If the organization as a whole can be viewed as an entity, the transactions are the stimuli which cause it to react. The more complex the stimulus, the more complex the reaction, and the longer its effects are felt.
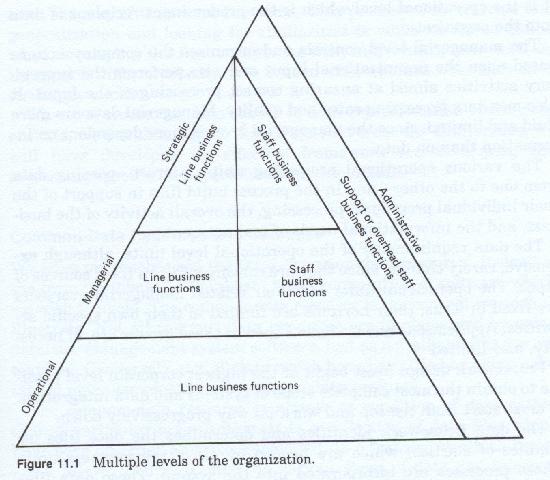
If the organization can be viewed as an entity, then it must also be viewed as one with multiple levels of awareness and multilevel personalities (Figure 11-1). It has multiple levels of control, each successively lower level having a differing level of data requirement, and a different, and less extensive, view of the organization. Each operational unit being almost self-contained acts as a separate entity for most of its activities. Obviously the higher the level, the more interrelated or integrated the business functions become until, at the very top, it is viewed as one continuous flow.
Level of Organizational Data
The different levels of the organization also have their own data and information needs. At the strategic level, the requirements are informational, derived from past data events and outside activities. At the operational level they are data oriented, specific, and derived from current data events. While management flows downward in the organization, data flows largely upward. At the operational levels all work occurs as a result of:
It is the operational level which is the predominant recipient of data into the organization.
The managerial level controls, and organizes, not only the company actions based upon the organizational input, but also performs the supervisory activities aimed at ensuring its correct processing. It also monitors processing rates and quality. Managerial data is more fluid and limited, that level being more dependent upon information than data.
The various operational processing units interact, passing data from one to the other, in the process building files in support of the their individual procedural processing, the overall activity of the business, and the informational needs of management.
The data requirements of the operational level units, while extensive, rarely change since they are contingent upon fixed sources of input.
The operational units and their related managerial overseers are fixed in focus. Their horizons are limited to their own specific activities. Applications and systems aimed at these groups are, of necessity, also limited.
Framework design must begin at the highest corporate level possible to obtain the most complete scope of systems and data integration. It must start from the top and work its way progressively lower.
The data framework identifies and determines the data files (or families of entities) which are needed by all of the business units whose processes are incorporated into the system. These data files must satisfy the needs of all the contributing units. The framework must distinguish between the files which must be used in common and the files which will be used privately. It must establish the timeliness of the data, the security constraints, most importantly it must establish that the data as filed or stored will be used and usable by all operational units.
Because many of these units previously gathered the same date which will now be consolidated in the common files, the data model must resolve various competing needs. It must also establish and determine from among the competing units which ones will be given responsibility for each of the data items and which ones will ensure that the needed data is gathered, edited validated verified and filed, and which of the competing methods will be employed to do so. In some cases it will determine that new procedures must be developed which incorporate the processing needs of all of the areas.
The data framework is one of the mechanisms for integrating the processing streams of dissimilar units. However, if we step back far enough, ignore the obvious differences and instead look at the similarities, we find that because they all operate within the same firm, all of the units and their data needs are sufficiently alike such that we can treat them as if they were the same. This process of abstraction, of generalization, of looking for similarities is the process we try to define when developing the frameworks. As with individuals, how they do things will differ markedly, from unit to unit, whereas what they do is strikingly similar.
When we create our data model or data representation of the data entities we can thus expect that if we first treat the similarities we will have developed an effective framework for developing the processing specific and operational specific details.
Common data resource and Database
We have purposely used the term common data resource instead of the term database. Database has a connotation of software which we wish to avoid. The common data resource is the concept we wish to illustrate. Not all common data resources are implemented using database management system software just as not all systems are automated. Conversely, not all data which has been filed using a database manager constitutes a common data resource.
The common data resource is a state or condition of data rather than a particular organization. It is a collection of data files which have been designed and constructed within a framework which recognizes, allows and facilitates the various types of data and information, and has organized the data into groupings which can be used equally by all processing systems, and which separates data from information, reference data from process data, common data from private data. The framework must contain standards for aggregation, data definition, data editing, verification and validation, data access, maintenance and use, etc.
Foundations of the Entity-Relationship Approach
Although the actual Entity-Relationship Approach will be explained in later chapters, a few words of background and introduction are appropriate at this point as to why these two core techniques were chosen.
The entity-relationship approach to data analysis is a zero-based, top down (or deductive) approach. This approach encourages the rethinking, rejustification and re-rationalization of each process, its related data requirements, its place in the business work flow and its conceptual content.
From the data perspective, zero-based design seeks to determine data requirements and rework the procedural mechanisms needed to satisfy those needs. These also rethink the sources of that data by regrouping data in other than usual ways.
Data frameworks help to satisfy what the organization needs to do to process the work of the business, divorced from how it is done. Frameworks examine why and when and what should be done, not how it should be done.
Entity Relationship Data analysis embodies a number of separate yet complementary approaches.
Each of these is a top-down approach, each starts with general or conceptual level components and successively determine the structure of the inherent detail based upon which a clearly defined set of rules.
Entity-Relationship analysis is divided into two phases, each phase of which can have multiple steps.
Phase one is known as the semantic phase. This phase performs a semantic analysis of the environmental descriptions and organizational determinants to extract the primary, focal or head-of-family entities of interest to the firm. Its intent is to produce diagrammatic and narrative representations of the real world objects or entities of interest of the firm. Each entity (used singularly) represents the entire membership of a family of like entities all of which are described in an identical or highly similar manner and which behave in an identical or highly similar manner.
The first stage is conceptual and disregards specific user views or specific user considerations. This stage roughly translates to determining the generalized data groupings.
The second stage is logical and incorporates user views of data and user considerations. This stage describes the entities and the relationships between them in terms of operational groupings of information or operational attributes.
The third stage populates the operational attributes with domain level data elements. A domain level element is a data element divorced from its physical representation or local usage name. Domain level documentation describes data element content rather than form.
In the semantic stage all descriptors are treated as equal attributes and no distinction is made as to keys, identifiers. indices, typing codes, etc.
At the semantic level any attribute can potentially be the entity identifier as long as it is populated with unique values, or which can be made unique when combined with other attributes, and so long as that attribute is present in every member occurrence of the entity set.
Because we are examining the behavior of sets of things, we can generalized and conceptualize about the things we need to describe them and how we must process them.
The next chapter presents a discussion of the Entity-Relationship model in its entirety. This presentation is for clarity, although the reader is cautioned that only the enterprise level is strictly speaking a framework element.
Data Directed Systems Design - A Professional's Guide
Written by Martin E. Modell
Copyright © 2007 Martin E. Modell
All rights reserved. Printed in the United States of America. Except as permitted under United States Copyright Act of 1976, no part of this publication may be reproduced or distributed in any form or by any means, or stored in a data base or retrieval system, without the prior written permission of the author.