Categories of Systems Design
There are two basic categories of system design techniques - those which are based on induction and those which are based on deduction.
Deduction is defined as the process of reasoning in which a conclusion follows necessarily from a stated premise: inference by reasoning from the general to the specific.
Induction is defined as the process of deriving general principles from particular instances or facts.
The products of inductive techniques are proved by deductive methods and the products of deductive techniques are proved by inductive methods. In some cases deductive techniques use inductive logic to guide them, in other cases inductive techniques use deductive logic to guide them.
Deductive techniques start from a set of stated general premises and by the application of certain sets of rules (or lines of reasoning) derive the specific results. If a deductive technique has an incomplete or faulty set of rules, or if it follows a faulty line of reasoning, it will produce erroneous results.
Inductive techniques take all or a representative set of instances and try to either prove the general premise or derive the general premise. If the instance selection is faulty or incomplete in some way, the general rules derived from them cannot be truly complete.
Since it is easier to know when the set of rules is complete or the line of reasoning is sound, deductive techniques are usually more successful.
Many methodologies successfully combine both inductive and deductive techniques. However using an inductive technique deductively or a deductive technique inductively can be as disastrous as using a legitimate technique at the improper time.
Many methodologies use a single technique, or variations of a single technique, e.g. decomposition (a deductive technique) in all cases with equally disastrous results.
Deductive versus Inductive Design
The two basic design philosophies, deductive and inductive, are reflected respectively in top-down and bottom-up design techniques.
Given the above, there is a basic conflict within the stated purpose of most system design processes. That conflict is between the desire to create a new system design logically, and by a set of rules, and to integrate and share processes and data (basically a deductive or top-down process), and the need to have systems provide the necessary specific support and service to the specific procedural (task) and data needs of the user population (basically an inductive or bottom-up process) which depends upon knowing all the tasks which are or should be performed and all the data which is, or should be used.
Business systems do not exist independently of the users. They are, in fact, defined by, and designed for the specific data and procedural needs of the users. Business systems are designed to perform specific tasks, in a specific manner, against specific data, and in a specific sequence. Since in most cases different groups of users do not and should not perform exactly the same work, they cannot share the same processing system unless that system supports all of their individual processing needs. The system must also be usable, as is, by each of the users regardless of their specific position in the overall business processing life-cycle Because each user or group of users must perform their tasks in a very specific way (according to the rules and procedures defined for those tasks), user processing systems are usually highly tailored collections of very specific task processes, arranged or sequenced in a very specific manner. These collections of processes in turn, must be structured around a higher level framework which is both rational and efficient and which supports the overall business and user specific needs.
System designs thus exist because of the individual users and their processing and data needs. The concept of user views in part III is predicated upon the idea that specific procedures or collections of procedures require specific data for their execution and that it is these user specific procedures and their specific data needs which are the basic components of and the driving force behind the system design. Part III presents the rationale behind the inductive design techniques.
User procedures are operational in nature and are written to support specific processing needs, and are by definition user task specific, however each task must also fit within the operational processing framework of the firm. Part II addresses the deductive development of data and task frameworks and the identification of those processing and data needs and the structuring of those processes and data to support the activity and task sequencing needs of the business as a whole.
The pressures to create practical process integration and sharable, central data files, are at the heart of the system design problem. The dichotomy between the requirement to develop procedural systems to satisfy the specialized data needs of individuals or groups of individuals, and the requirement to generalize data so that it may be shared amongst multiple groups of people with diverse needs gives rise to a variety of techniques (methods), and collections of techniques (methodologies, although strictly speaking methodology means the study of methods) to resolve the conflict.
Top-down versus Bottom-up
Although it may appear that top-down design techniques are in conflict with bottom-up design techniques we shall see that they are in fact mutually supportive. During the analysis phase we use top-down or deductive techniques to determine the individual task components of the existing systems and inductive or bottom-up technique to determine the inherent logical structure of the data. During design, task restructuring can be accomplished from the bottom up (inductively) by the structuring of those tasks and any new ones we may have identified during examination and study into longer and longer task sequences. These task sequences can be given the general label of activity, and thus the structuring process becomes one of determining successively longer activity sequences. We can also design top-down or deductively (by applying rules of life cycle activity logic) to develop a framework or guiding logic to sequence those highest level (longest) activities.
Similarly, the top-down structuring of data files requires some framework or guiding logic to drive the deductive process. The logic which is most effective for top-down data structuring is an application of classification techniques as we shall see in later chapters. Bottom-up data design includes determining user data groupings and applying normalization techniques (or data normalization logic) to re-group all the data thus identified.
Bottom-up data or inductive data structuring requires sufficient instances of task definition to guide identification of the detail and later general data element classification scheme which is represented by the data structure. These efforts are neither mutually exclusive nor contradictory. They are separate processes each of which is intended to achieve an identifiable goal, the data classification structure, and like any process they have specific data and processing needs. They are two views of the same plane, one from above and one from below. The development of the data structure is either an inductively driven deductive process or a deductively driven inductive process and is one of the few design tasks which must combine both induction and deduction concurrently.
This interaction between induction and deduction simply reflects the central role of user specific processing views in the data structuring process and the need to marry both process and data identification in one set of activities in order to develop an effective data model.
As we have seen top-down and bottom-up are approaches which apply to analytical techniques. As we have also seen, the actual structuring of task aggregations into processes and systems is in reality most effectively and efficiently accomplished using deductive techniques applying rules which follow horizontal lines which reflect business or data entity life cycles. Since it is the life cycle which supplies the set of rules which are most stable, easiest to determine and easiest to apply.
Data design consists of elements, properties (groups of elements also called attributes and characteristics) and entities (labels for groups of characteristics which are the data representation of a real world or conceptual thing). Data design also includes development of entity family trees to assist in classifying and cataloging the entity family members and to use that tree to develop a generalized data structure which can accommodate any member of that family.
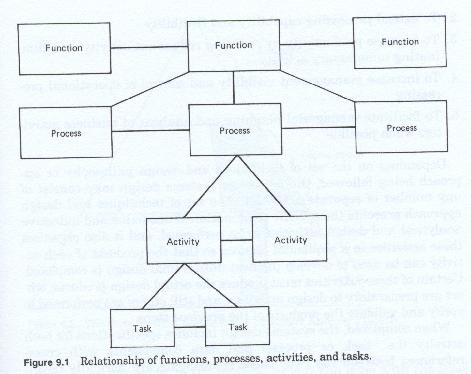
Procedural design consists of tasks, activities (a label for a specific set of tasks in a specific sequence) and grouping (a label for a group of specific activities performed in a specific sequence). The design must identify each of the detail tasks to be performed, how they must be grouped into activities, and how activities must themselves be grouped (figure 9-1). Since an organization can apply many rules for classifying the activities, the groupings of activities, top-down or bottom-up, is somewhat arbitrary, unless it is based on entity life cycle. Assignment of responsibility for groups of activities is a management decision and is disconnected from the process of logically grouping the activities.
The most detailed items of the design are always a series of detail procedures which identify each task to be performed and the detail data and data access requirements needed to store, retrieve and maintain that data. These procedures will also identify the tangible and intangible resources needed to perform each task and the manner in which the task results are to be recorded. These procedures will describe each form for gathering or recording data, how that data is to be validated, recorded and filed. It will describe who may use the data and how it may be used.
These procedures together implement the business rules, functional objectives, and fulfill the processing requirements of the firm. These rules, objectives and requirements are based on the business's need to collect and maintain data about the data entities of the firm, how they are related to each other and what the activities of those entities are. Between these detail task procedures and the strategic plans of the firm, are many levels of detail (top-down), levels of aggregation (bottom-up) and forms of presenting the design products. The closer the design approaches to the strategic business plan the wider its scope, the broader its content and the less detail it contains.
Design Goals
Thus, the systems designers must determine: what tasks need to be performed when, how and in what sequence those tasks are to be performed what resources are needed to perform those tasks.
The design goals are:
Depending upon the set of techniques and design philosophy or approach being followed the process of system design may consist of any number of separate activities. The set of techniques and design approach specifies the specific combination of deductive and inductive analytical and design activities to be performed, organizes those activities in a sequential manner such that the products of each activity can used to develop the next until a final design is completed. Certain of these activities must produce the actual design products, others are preparatory to design activities, and still others are performed to verify and validate the products of the previous steps.
When completed, the system design includes specifications for both activity (i.e. task or process) and data components with cross references between the two. These components are normally developed concurrently, however each different approach schedules the design tasks in a different sequence. Different design techniques are selected by each approach to develop each type of component and to accomplish each systems design activity. These differing selections of design techniques may sometimes result in different forms of products, and in substantially different system designs.
System design begins with the identification and organization of business requirements extracted from various managerial level sources. These sources specify the manner in which management would like to see its business activities supported, the goals and objectives it would like to see its organization achieve and the constraints under which the organization operates.
Various methods and procedures have been developed by systems analysis and design specialists to identify develop and document the requirements and specifications of the business system and to identify and develop the business activities and their preferred or necessary sequence. These methods and procedures organize the analysis and design activities into levels, stages or phases which generally reflect a top-down or general to specific approach. Although each level represents the same scope, their differences lie in the levels of detail being represented.
These levels (figure 9-2) are named to reflect the level of detail to be reached when that phase is completed.
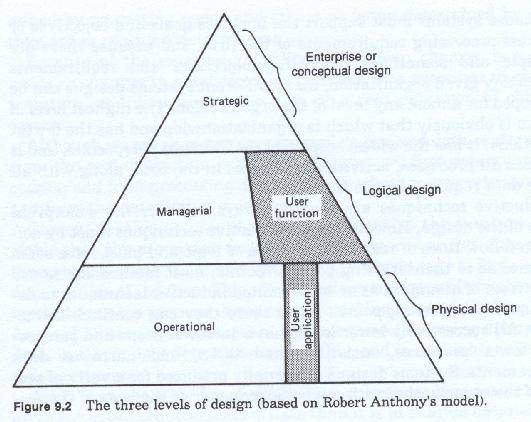
Generally speaking the terms conceptual or architectural level are considered to be the highest. This is the level with the least detail. The physical level by contrast is usually considered to be the level with the most detail and is thus the lowest design level.
The initial starting point, whether it is called the enterprise, conceptual, framework or architectural level, is one of the most critical pieces of the system design process. It is here that critical decisions are made which influence and direct all subsequent steps.
It is here that the design team determine and document the goals, objectives, activity life cycles, the focal data entities of the business and the interrelationships between them.
In other words, they use the goals and objectives of the firm and its management to determine:
Once these frameworks have been established, each activity can be decomposed vertically, since its objectives and placement within the business and data life cycles are clearly known.
Because systems must support the business goals and objectives or business processing requirements of the firm, and because there are multiple and sometimes conflicting objectives and requirements within any given organization, many different system designs can be developed for almost any level of the organization. The highest level of system is obviously that which is organization-wide which has the fewest variations. This level has the widest scope and the broadest perspective. This design level includes all processes, activities and tasks in the firm, along with all of the data required by the firm
Deductive techniques are almost always used for the conceptual phase of the design. However since deductive techniques must by definition follow lines of reasoning or rules of logic, and must have some guidance as to its starting point or points, most of them use either a set of assumptions or some limited inductive techniques to determine those starting points and from those starting points they can continue deductively. All successively lower levels have narrower scope and perspective, fewer processes, activities and task, and narrower data requirements. Systems designs are usually produced for a vertical section of the organization with a specific manager at the apex of the section.
Data Center Versus Process Centered
Some design efforts attempt to develop the systems along a horizontal section of the firm. These systems are cross functional, in that there is no single manager to approve or finance the system design effort. In the horizontal designs, sometimes called subject area designs the design team may be either process centered, or data centered. Data centered design focuses on a data entity or a group of very tightly related data entities and all of the supporting tasks needed to support the acquisition, maintenance and dissemination of data about that entity or entities.
Process centered design focuses on a specific type of processing such as a business area. A business area is a concept which represents the universe of business goals, objectives and requirements, systems, processes, activities and tasks related to an area of interest of the firm. Business areas are thought to be organizationally neutral. Although the focus is on processing, practically speaking even process centered business area designs have at their core some major data entity of the firm.
Almost all business systems, automated or otherwise, are designed to process data and thus there is a very tight relationship between data and process. Although some view data as being determined by processing needs, and others view processing as being determined by data, they are in reality co-determinant.
Because of the extreme volatility of business change, new data needs, or changes in old data needs mandate new processes to gather maintain and disseminate that data or a reexamination of old processes.
Although we speak of process centered design and data centered design, the real distinction is between whether we determine processing and from processing derive data, or we center on data and from that derive processes.
Current thinking states that the data needs of the firm are more stable than the processing needs, and it is easier to project data needs than process. To project data needs we need only focus on the data entities of the firm. This view sidesteps the issue of whether data needs determine processing needs, or whether processing needs determine data. As we shall see in later chapters, in some cases processing determines data, in others data determines processing and in still others they are co-determinant.
Aside from the stability of either data or process, it is easier to analyze the detail requirements of data than it is to analyze detail processing requirements. If we contrast the analysis process with the design process, one thing become evident. During analysis we can see what is being done. It is easy to check the results of the analysis against the current environment. That current environment not only determines when the analysis is complete (i.e. have we documented all current tasks, data and problems) but we also know whether the
analysis is accurate. The functional decomposition process during analysis need only result in the end tasks which are being performed, the intermediate decomposition levels are almost meaningless. We can compare the documentation to the real world to determine its accuracy.
During the design process the end result is not known, nor do we necessarily know when we have made the correct decomposition decisions. We may not even necessarily know when we have completed the design, although there are many methods for testing the consistency and accuracy of the design models.
Much of the terminology used in current methodologies is biased, vague, or worse, multiply defined. The design process has a known start, an unknown end and multiple ways of achieving an end. If the end is not known, how do we know when we are finished?
The data centered design techniques used in the remainder of this book will achieve the traditional design objectives, however different terminology will be used. The reason for this use of different terminology is not to confuse, but to cause the reader to think through both the terms and the concepts.
The techniques presented do not constitute a methodology, nor are they necessarily new versions of currently popular techniques, but they are all variations of traditional analysis and design techniques which have been modified to illustrate the techniques and objectives of data centered design.
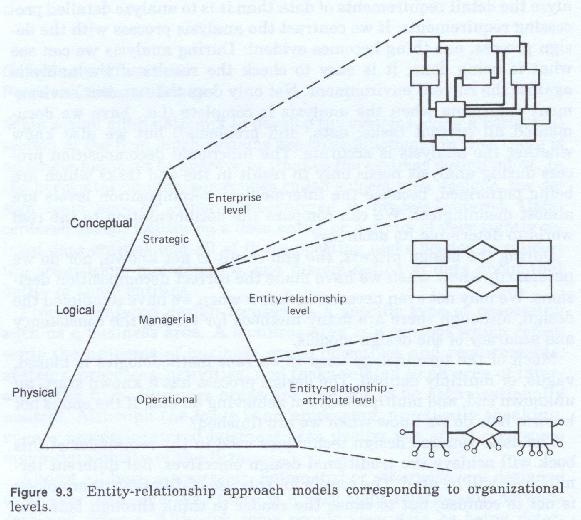
The core techniques are centered around the entity-relationship approach to data analysis and design and work flow or business life cycle analysis (See figure 9-3).
Framework Development
Framework development is critical to the design process. Because of the uncertainties inherent in the design process, and because of its need to project as far out into the future as possible so that the firm achieves maximum usefulness from the system once implemented, designers must use all their knowledge and skill to project future requirements.
Systems design is part art and part science, unfortunately more art than science. Designing a new system has been likened to shooting at a moving target from a merry-go-round.
All systems designs must start with understanding the environment, the driving forces and goals objects and constraints which cause the firm to need the system at all. All functions, all data requirements, and all processing must ultimately support and be derived from these driving forces.
These driving forces, goals and objectives are then translated into a framework or architecture which describes in general terms the flow of the work, and the general activities which will be performed and the sequence in which they will be performed, and how the designers see the various business functional threads interacting. This framework also identifies and describes the major data entities of the firm. These data entities will become the major focus of data collection and data processing. This framework also depicts how these essential or focal entities will interact with each other.
These frameworks are developed in an organizationally neutral, functionally neutral and technology neutral manner. This is sometimes called the conceptual level.
Logical Design - User Perspectives
Once the framework is complete the user perspective is introduced and detail is added to the conceptual activities and data entities. This is the logical level, and it is here that the business rules are introduced, and incorporated into the design components. Like the framework level, the logical level is also technologically and organizationally neutral.
The logical level is complete when all user requirements have been stated and all user specifications have been identified, defined and documented. The final product of the logical level is a set of detail models, detail narratives explaining those models, and a set of detail processing specifications at either the activity or task level.
Chapter 10 discusses some of the more common driving forces which determine the scope, content and objectives of a design. Chapters 11 and 12 present a discussion of the data framework and the entity-relationship model. The entity-relationship model is presented in its entirety, although the reader is cautioned that only the enterprise level is strictly speaking a framework element.
Chapter 13 presents a discussion of the task or activity framework and the activity life cycle or work flow structure method of presentation.
Classification Emphasis
Both of these frameworks are developed deductively and although they incorporate the application of different systems design techniques, they incorporate a single common philosophy - that of classification.
Simply stated, classification when applied to data implies that the concept of identifying an entity and developing the structure of its family of entity subsets or subtypes involves applying a label to a structure of classified, structured, groups of data characteristics, and that each group of data characteristics can be referenced by a name or label which we will call the entity name. This is based upon the idea that entities are distinguished from each other, both across families and within families by:
Classification when applied to tasks implies that the concept of identifying a high level activity (called alternatively mission, function, systems, or whatever) and developing the structure of its family of activity subsets or lower level activities (called alternatively functions, systems, processes, activities, or whatever) involves applying a label to a string of classified, structured, groups or strings of tasks, and that each group of tasks can be referenced by a name which we will apply to it. This is based upon the idea that activity strings are determined by and distinguished from each other, both horizontally and vertically by:
Because these groupings or classifications of data, and these strings of tasks can be determined by any number of rules (by any number of sets of rules of logic) and because these sets of rules can and usually are applied concurrently and because within these structures any given element can not only have many children but also many parents (through shareability or reuse at different times) we call the resultant structures polyhierarchic.
When we compare the processes of system analysis to those of system design there is one apparent and overriding difference which serves as the major determinant as to the activities of each. Analysis deals with current data (as reflected by file and document contents) and activities or tasks (as reflected by what people are actually doing and when and how they do it). Design, while it deals with some of the same data, tasks and activities, deals with ideas and concepts of new data and new ways of doing things (activities).
Put another way, analysis deals with real things which can be observed and tested, and the descriptions of those real things can be compared to the things being described. Design deals with ideas which can be tested against the descriptions of those ideas only with great difficulty, if at all.
The need within the design process to describe ideas and concepts makes the design process much more difficult and much harder to describe.
The Goals and objectives of design, rationalization, justification and integration may also change some of of our ideas about the components of a system and the definitions of those components that we used in analysis, in particular the definitions of function and process and our concepts of what they really represent, for in fact they represent different things during analysis than during design.
The goal of integration of systems activities breaks the traditional linkage of process (something used internally by and therefore under the control of a function) and function (something which uses one or more processes) and substitutes the notion of processes, and systems which span functional lines. Thus we may have functionless systems in the traditional sense and we may have to create new ideas or managerial concepts to replace the idea of functions, systems, processes and activities as something predetermined by both organizational lines and single user processing needs.
Data Directed Systems Design - A Professional's Guide
Written by Martin E. Modell
Copyright © 2007 Martin E. Modell
All rights reserved. Printed in the United States of America. Except as permitted under United States Copyright Act of 1976, no part of this publication may be reproduced or distributed in any form or by any means, or stored in a data base or retrieval system, without the prior written permission of the author.