Relationship Identification
The second major phase of data analysis is the identification and specification of the relationships (figure 14-1) between the entities of interest to the firm. These relationships serve several purposes. First they place the entities in context and second they help to delineate the business rules of the firm with respect to those entities. From the record model perspective, each relationship identifies a relationship or cross reference which must exist between the files which will ultimately be created to contain the data about those entities.
|
Figure 14-1 Definition of a relationship
The various data models, both real world and record, are developed in leveled steps beginning first with a model of the real world entities and concluding with a model or models of the data record entities. Each model portrays a different type of entity, and a different perspective of the entities. Entity types must not be mixed within a given model, however the analysis team must maintain continuity between the various leveled iterations of the models. That is, the team must maintain the relationship between the various components as the models progress from portraying the entity families, through the portrayal of the entity roles and groups through the translation of the real world entities into sets of data records for final translation into a physical data model for a particular DBMS.
This task is made more difficult when either entity names are changed or when entities are split or combined during the analysis. This process however is identical to the maintenance of continuity between the functional requirements, the system design specifications, program code and system test cases on the process side of the design. The process continuity is relatively easy since most design efforts use a straight forward decomposition method to translate from one level to another.
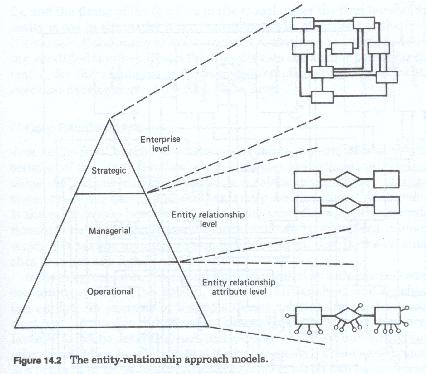
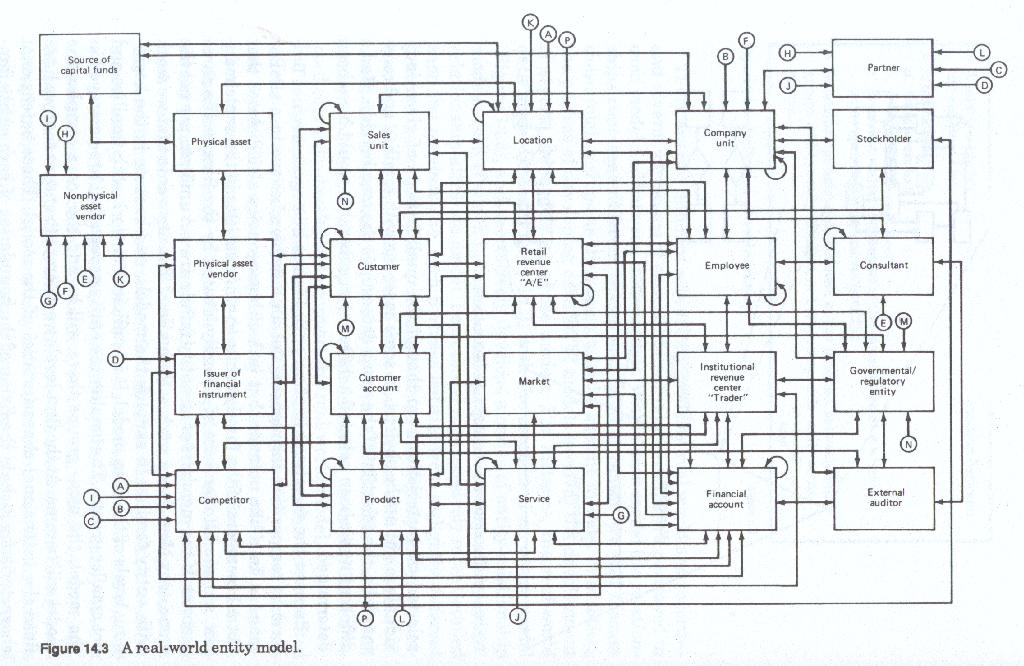
There are two different sets of data models - real world and record - and several variations of each. Different relationships are portrayed in each model and between these models. Within each model the relationships represent different things and for that reason we will discuss these relationships as they pertain to the specific models. In addition, the process of developing each set of models involves the development of several sub-models, or phase models. For instance, the Real world data model begins (figure 14-2) with the creation of an entity model (figure 14-3), and successively develops a series of entity relationship models, each of which in turn are used to create a corresponding entity-relationship attribute model. Each model is successively more detailed than the previous one, each portrays entities from a slightly different perspective, and each one uses uses relationships in a slightly different manner. In a like manner the record data model begins with the set of real world data models and depending upon the DBMS or file management system chosen, will develop a set of models using as its entities the record sets to be developed to support the real world model.
The first phase of the development of the data models concentrated on the exploration and definition of the extensional aspects of each entity family. This was accomplished by the selection of a label to be applied to each family and the development of a definition which described as precisely as possible the population of each family. The family populations were described in terms of the characteristics that each member must possess to be considered for membership. Although the term family is recommended for use when dealing with the extensional entity, the entity is more closely analogous to a cousins club where several family groups are joined together because they have in common some ancestral connection, or they are related by marriage. Many cousins clubs bear the surname of the predominant family even though individual members many have other surnames. Entity families are similar in this respect since a larger group is assembled because of selected characteristics even though the qualifications of given individuals might not be obvious. In some cases, as with families and cousins clubs, the selection of the name determines the membership. Had a different name been selected a different membership would have been determined.
Because the membership of an entity is not homogenous, not uniform in composition throughout, not all members behave in a similar manner. In a like manner that lack of homogeneity also dictates that not all members of the family relate to other entities in the same manner, nor are all members of a family treated by the firm in the same manner. If the members of an entity family are not uniform, are not the same, why then do we work with families? The answer is that we work with entity families to simplify the models, and because in the beginning levels of the data model, it is sufficient to work with families and no smaller groups. The smaller the entity groups that are portrayed in the model, the more groups there will be and the more complex the model will become. At the first levels we attempt to ensure that we have fixed the extensional characteristics of the model. These extensional characteristics include the fixing of the boundaries of each entity family, and the fixing of the families in the model. After the first level, if the entity is not in the model it is assumed not to be of interest to the firm. Conversely, if the entity is in the model it is assumed to belong to one of the identified families. These families provide the anchor points for the model, for the expansion and decomposition of the model, and for the eventual development of the files of the firm.
N-Nary relationships
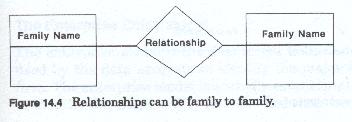
Just as the first levels of the data model define the extensional characteristics of the entity families, so to it defines the extensional relationships. An extensional relationship is a relationship (figure 14-4) between one entity family and another family. An intensional relationship is the relationship between entities of the same family. Although relationships can have many participants, and can be expressed in many ways, it is easiest to portray them in binary form, that is, the relationship between one family and another.
In its simplest form, a relationship is expressed as a simple sentence, containing a subject (en entity) a verb (a relationship) and an object (an entity). An example of a simple binary relationship might be Student (entity) attends (relationship) classes (entity). A more complex relationship can be described such as students (an entity) and faculty (another entity) buy (a relationship) books (an entity). This is an example of a tertiary, or three way relationship. This example can be made even more complex if we add the phrase "from the bookstore (an entity)." Obviously such complex relationships are difficult to depict in diagrammatic form, although they are relatively common, and relatively easy to state.
A relationship is defined as any association, linkage or connection between the entities of interest to the corporation. A relationship must also be a) of interest to the corporation, b) capable of being described in real terms, and c) relevant within the context of the specific environment of the firm. A relationship is any interaction between the entity occurrences of one entity family and the entity occurrences of another entity family. Neither entity families nor entity groups relate to each other. Relationships are between individual entity occurrences.
Intensional versus Extensional Relationships
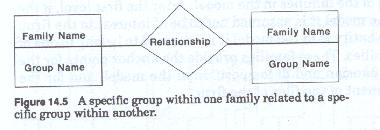
A given relationships may be either extensional or intensional, but intensional and extensional relationships should not be mixed within the same model. Extensional relationships are defined as those relationships which represent the association between one entity family and another. These relationships depict how the various entity families of interest to the firm interact with each other (figure 14-5 and 14-6).
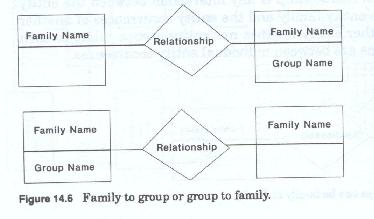
A relationship exists when an association is established between two entity occurrences. For example, when it is established that a product is purchased from a specific vendor, the firm has established a relationship between a vendor and a product. This association can be generalized to state that products are purchased from vendors. That is, any given product can be obtained from any given vendor. Since the firms usually has a need to know which product is purchased from which vendor, when the vendor file and the product files are created, provision is made to maintain that association. A given vendor may vend multiple products to the firm, and the firm may purchase a given product from multiple vendors. The relationship however is vendor (an entity) vends (the relationship) product (an entity), or conversely product (an entity) is purchased from (a relationship) vendor. The specific vendor-product pairings will be established when both vendors and products are added to the files, and the implementation may differ depending upon how the files are created, but regardless of implementation, the relationship remains the same.
One of the purposes of the data model is to identify and define the parameters of each of the relationships that are known to exist, that are suspected to exist, or that the firm wishes to create. Because the network of relationships between entities can be extremely complex, and because relationship identification and definition are a critical part of good file design care must be taken to ensure that all relationships of interest to the firm are incorporated into the data model.
The modeling of relationships (figure 14-7) is thus an integral part of the modeling of data and is built into the process. The data model is composed of a series of discrete, but related submodels, each of which models real world entities or data records from a different perspective, and models the corresponding relationships from those perspectives as well.
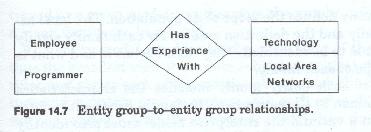
The importance of relationship modeling
Many data modelers pay little if any attention to the modeling of relationships. Those models that do include relationships pay more attention to the properties of the relationships than to the relationships themselves.
Relationships provide the mechanism for associating data from multiple subject files. Each relationship defines the mechanism for taking data from one file and combining it with data from another file. This ability is critical to the ability to edit and validate data in one file, using data in another. Relationships also provide the ability to provide the personnel of the firm, both operational and managerial with reports combining data from multiple files.
The Enterprise Entity model
The enterprise model is the first model to be developed. This model is used by the data analysts to identify the major entity families of the firm. The enterprise model is a wholly extensional model. Its purpose is to identify the major entity families and their boundaries. The boundary of an entity family defines the scope of its population. The label assigned to each family, and the definition created for each family, signify how its population is to be identified. They define what is and what is not within the scope of each family.
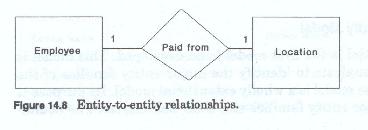
The definition of each entity family includes the characteristics which must be common to all members of the family. Since entity families do not exist in a vacuum the enterprise model must also identify the interfamily relationships. Each entity family must relate to at least one other entity family, but does not necessarily have to relate to every other entity family. The enterprise model begins the process of relationship modeling by identifying which entity family pairs are related. A relationship (figure 14-8) is some association or connection between a member of one group and a member of another group. Relationships are established and maintained at the individual entity occurrence, or family member level. That is, specific instances in one family are related to specific instances in another family for a specific reason. At the enterprise level, because of its global, general, nature it is sufficient to identify that one or more relationships exist, although the modeler must always remember that relationships are always implemented between individuals.
All members of an entity family may relate to all members of another family, or the relationship may be limited to only some members of the other family. From the enterprise perspective how many relationships exist and how those relationships are defined is not material. In fact because the membership of each family is so usually diverse and because the relationships can be so complex, to attempt to model each relationship at this level is usually futile, since many relationships are between members of specific entity groups within the families and not between the families as a whole.
When the enterprise model is drawn, it consists of symbols (usually rectangles or boxes) each of which represents a given entity family, with a line between each pair of related symbols (families). The line carries no other information other than that one or more relationships exist between these two families. Even with this limited amount of information being portrayed, enterprise models can become somewhat complex. This complexity is due to the number of families portrayed in a given model and the number of families to which a given family can be related.
The entity model provides the broadest view of the data model and thus the broadest view of the data subjects (entities) of the firm. It identifies and places each of the entities about which the firm need to capture and maintain data in context with each other. If a pair of entities are not related within the enterprise model then there is no business relationship between them that the firm is interested in. Thus in no other model will any member of either family be related, in any manner. If a pair of entities are related through the enterprise model than at least one relationship of interest to the firm exists between one or more members within each family. The model does not carry any information as to the extent or number of the relationships nor the size or complexity of each family.
In some respects the enterprise model is the easiest model to prepare in that it is simple to prepare. In other respects it is extremely difficult to prepare in that it is not complete until all entity families have been appropriately identified, labeled and defined.
In some instances, depending upon how the family membership has been defined, members of a given family may be related to each other. This is known as a recursive relationship. Some examples of recursive relationships might be the "manages" relationship (one employee manages another employee) or the "owns" relationship (one company owns another company). Recursive relationships (figure 14-9) are shown as a curved line both ends of which are connected to the family symbol. As with the other relationships portrayed in the enterprise model, the recursive relationship line may represent one or more relationships.
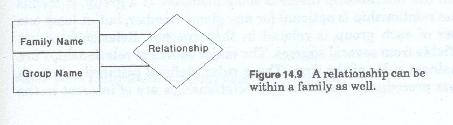
The enterprise model is the first of a series of design and analysis models which begin by describing in real world terms what the firm requires data about. The series of models is completed when the analysis and design team produced the last record model which describes how the data required by the firm is to be stored. This is sometimes also called the implementation model.
This first model is not strictly speaking a data model, in that it does not describe data. Rather it describes the major subjects about which data will be gathered. Other models will describe the data that must be gathered and maintained about these subjects, how that data is to be organized into records, and how those records will be organized for storage by a particular Data Base Management System.
Just as each model describes a different aspect of data or its organization, so to each model describes a different aspect of the relationships which must ultimately be maintained by the same DBMS which stores that data. Some of these models will describe the relationships between entity families, others the relationships between entity groups, still others the relationship between the data that describes a specific entity group or family, and still others the relationships between the records used to store that data.
In all but those models which depict how the records are organized for storage within the DBMS, a common set of rules apply. In the record storage models the rules of the particular DBMS must apply and thus a given data model may result in several different types of record storage models depending on which DBMS is used to store which data.
Because there are several different types of data storage models or record models - hierarchic, relational, network being the most common types - and because regardless of which record model is employed each vendor has of necessity implemented their version differently, there are only general rules which can be stated that cover all implementations.
The entity-relationship entity model
The entity-relationship model represents the first level of decomposition of the data model. In this model each entity family is decomposed into its major entity groups, and each relationship between the groups that is of interest to the firm is identified and defined. The model at this level defines general statements of relationship between between each related major group. A general statement of relationship covers a specific relationship between members of one group and the members of another group. A general statement of relationship states that the relationship may exist or must exist, and it identifies the groups that are related but it does not identify which members of each group are related to each other.
The relationship may involve some or all members of each group (figure 14-10). When the relationship involves all members of a group, it means that each member of the group must participate in that kind of relationship with a member of the other group.
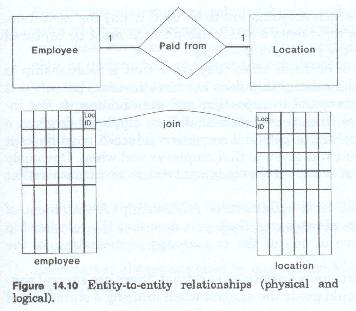
When the relationship involves some members of a group, it means that the relationship is optional for an given member, but at least one member of each group is related in that manner. Relationships are identifiable from several sources. The major source of relationships are the business rules of the firm. These rules defined primarily through business procedures, specify which relationships are of interest to the firm, which members of which groups can participate in which relationships and under what conditions those relationships must (or can) be established and maintained (figure 14-11). For instance, the rules of the firm might state that the firm must maintain a list of three possible sources for each item it purchases. The rules almost always state that the firm must maintain records about which vendor supplied which items, and when. In most firms the rules also state that records be maintained about which accounts are to be used to pay for each item. Each of these rules represents a relationship which must be captured and maintained by the records of the firm.
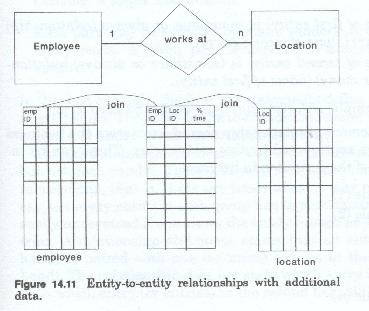
In other cases the business rules may state that a relationship is optional. That is the relationship does not have to exist, but when it does the firm is interested in capturing and maintaining it. For instance, the business rules might state that if an employee is given a piece of office equipment (a personal computer) record must be kept as to what equipment was given to that employee and when. Obviously those employees that are not given equipment do not participate in that relationship.
We have used the term statement of relationship. A statement of relationship consists of two parts. Each part describes the relationship for the perspective of one of the two groups participating in the relationship.
Although there are many variations in format, there are several general rules which should guide the analyst when drafting a statement of relationship:
First, the definition of a relationship should provide the following information:
Second, the definition should be written in the following general form:
In the above sample, (relationship) must be a valid verb form.
Third, the statement of relationship should enumerate the business rules which represented by this relationship. These can be included as part of the definition in list form.
Fourth, the statement of relationship should include any business rules which provide conditions which limit when the relationship can exist, how many entity occurrences can participate in the relationship, or under what conditions the relationship can be established.
Finally, each statement of relationship should be self contained and not dependent upon the existence or content of any other statement of relationships or definitions other than those of the entities involved in the relationship, or existence condition statements.
For example, the following are simple statements of relationship:
Each employee is always managed by one employee.
Each manager always manages one employee. A manager sometimes manages many employees.
Each part is always supplied by one vendor. Each vendor may supply many parts.
These statements reflect a one to one relationship, a one to one relationship with an optional one to many relationship and a one to one paired with a many to one relationship.
Each relationship can thus be viewed, and should be viewed from both side of the relationship. Each relationship has two participating entity groups (A and B, left and right). In order to properly assess and define the relationship statements it must be stated from both sides. In most cases, these left to right or right to left statements will be complementary, however they should always be stated both ways for clarity.
Consider a slight modification.
Each part may be supplied by many vendors. A vendor may supply many parts. A given part occurrence is always supplied by one vendor.
In this last example, the first two statements define the group to group relationships. They also define the conditions under which parts are acquired and under which vendor supply parts.
The third statement delineates a specific case which covers each part, but not each vendor. The words may or sometimes identify a conditional relationship, i.e. there are times when it may not exist. That is to say, not every entity in each group has to participate. This can be more easily understood if one views the entity groups as separate lists of entries. A relationship statement states that an entry in one list (left hand) is paired with one (or more) entries in the second (right hand). The relationship does not state which entry in list one is paired with which entry (or entries) in the second list. All it states is that the relationship can or must exist. It is the user procedures and the actual data which the user enters which create or implement the actual relationship pairings.
Most relationships are not complex in that they can be stated using rather simple general statements. However, what makes the relationship model difficult to develop are the following conditions:
Data Analysis, Data Modeling and Classification
Written by Martin E. Modell
Copyright © 2007 Martin E. Modell
All rights reserved. Printed in the United States of America. Except as permitted under United States Copyright Act of 1976, no part of this publication may be reproduced or distributed in any form or by any means, or stored in a data base or retrieval system, without the prior written permission of the author.