
Entity Analysis
Characteristics and Attributes
Identification and definition depend upon the use of characteristics and attributes. We have used the terms characteristic and attribute without really defining them or the differences between them.
An attribute is some aspect or descriptor of an entity. The entity is described in terms of its attributes. An attribute may contain one or more highly interrelated data elements. Attributes have no meaning, existence or interest to the firm except in terms of the entity they describe.
An attribute may be a very abstract or general category of information, a specific element of data, or level of aggregation between these two extremes. Most attributes appear as clusters of highly interrelated elements of data which in combination describe some aspect of the entity. The data values of attribute data elements are not critical to the data model and in most cases they are unique to an entity occurrence. The data model must however document the valid ranges of the data, its format, etc.
A characteristic is a special multipurpose, single data element attribute whose discrete values serve to identify, describe, or otherwise distinguish or set apart one thing or group of things from another. Within the data model, all valid data values of each characteristics must be identified and documented. These values form the basis of entity classification, which controls processing, data grouping and entity identification. Since both the characteristic name and its values are of interest, and since as we shall see later, attempting to diagram the hierarchy, or rather polyhierarchy, represented by these characteristics is difficult and misleading, characteristics are diagrammed as a "T-list." The standard form of the T-list and an example are illustrated in figure 13-1.
The most definitive characteristic is the identifier (or key) whose values distinguish one member from another, or put another way, the unique range of values of the identifier characteristic creates the smallest most restrictive group - a group with only one member.
Both entity family and entity group characteristic are mandatory, and each occurrence of a characteristic must have a valid value for correct identification, processing and data grouping.
Kinds of Characteristics
Classification science uses the characteristics of things as a means for grouping them. Data modeling uses attributes for describing things and characteristics for grouping both entities and attributes.
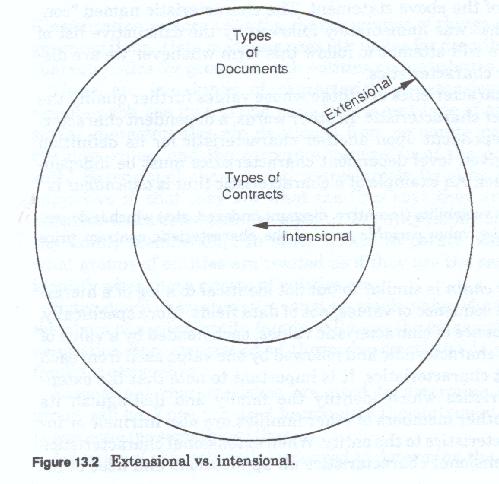
There are two kinds of characteristics, - extensional and intensional - each has its use and each has its own type of analysis. Extensional characteristics are developed from corporate policy, corporate business rules and the corporate perception of the entities it deals with. Extensional characteristics are largely fixed by policy and are subjective in that they are what the firm says they are. Extensional characteristics determine the criteria for entity family creation and entity family membership. In other words, corporate policy determines what groups of entities are treated as if they are the same and how to identify what those groups of entities are.
Extensional characteristics must be single value characteristics.
All members of a given entity family will have the same extensional characteristics since possession of those characteristics is the criteria for family membership.
Extensional characteristics are used to determine how large the group will be. Extensional characteristics are used to complete the statement - An employee is someone (or something) that....
Intensional characteristics are used to determine the differences between members of a family, how they are to be grouped, for purposes of processing. All members of a given group within an entity family will have the same intensional characteristics. Intensional characteristics determine the various kinds of members, their identifiers, and their relationship to each other. Intensional characteristics form the bulk of the characteristics of interest to the firm. It is the intensional characteristics which are used to construct the entity family model. Unless otherwise noted all characteristics discussed in the remainder of this portfolio are intensional.
Intensional characteristics are used to describe and categorize the different kinds of employees.
Dependent and Independent Characteristics
Intensional characteristics may in turn be either dependent or independent. Independent characteristics are independent of each other. All characteristics between chains, and at the first level (below the family) within a chain, must be independent of each other.
Examples of characteristics that are independent are:contract price terms (fixed price or variable price)contract payment type (lump sum or installment).
Note the form of the above statement. The characteristic named kind of entity was immediately followed by the exhaustive list of legal values. We will attempt to follow this form whenever we are discussing specific characteristics.
Dependent characteristics are those whose values further qualify the values of another characteristic. In other words, a dependent characteristic is value dependent upon another characteristic for its definition and use. At a given level dependent characteristics must be independent of each other.
An example of an characteristic that is dependent is:type of price variability (incentive, discount, indexed, etc.) which is dependent upon the value variable price of the characteristic contract price terms.
A characteristic chain is similar to but not identical to a leg of a hierarchy. A chain is a sequence of values, not of data fields. More specifically, a chain is a sequence of characteristic values each headed by a value of an independent characteristic and followed by one value each from each of its dependent characteristics. It is important to note that the extensional characteristics which identify the family and distinguish its members from other members of other families, are also intrinsic or intensional characteristics to the entity. When extensional characteristics are used as intensional characteristics all applications and uses of intensional characteristics apply, including chain heading. Figure 13-2 illustrates the classification of the contract entity by the characteristic price terms, the further classification of price terms by type of price variability, and one of the characteristic chains resulting from that classification.
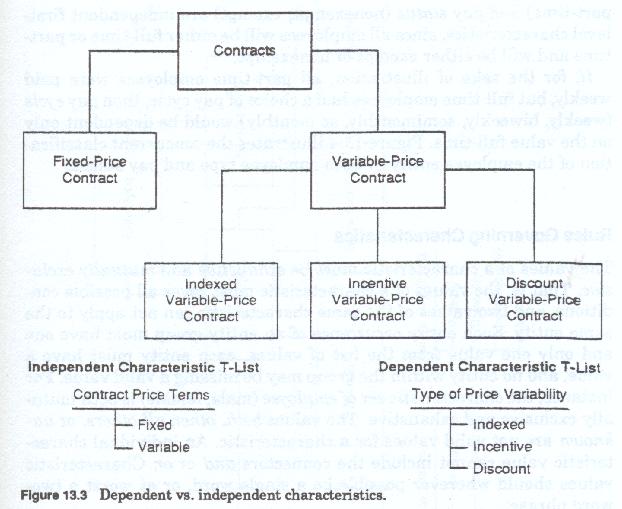
For purposes of grammatical correctness, chains are read upward rather than downward. For example the following chains are (figure 13-3) formed from the above:
Each of the above chains is formed by the use of one or more characteristics, and each indentation level of each chain names a group of contracts or kinds of contracts. Each level of indentation indicates a set of more restrictive groups formed from the group at the preceding level of indentation.
A characteristic can have multiple dependent characteristics each of which is independent of each other, however these are still dependent characteristics. Each chain of characteristics from the base begins with an independent characteristic followed by one or more dependent characteristics.
Characteristic levels
We have and will continue to refer to characteristics by level. A first level characteristic must be capable of grouping all members of the entity family population independently of any other grouping of the same population. Second and succeeding level characteristics are dependent in that they can only group within a first level characteristic. It is this representation of qualification levels (length of qualifier chain) and the entity groups which are determined by those qualification levels, that gives rise to the notion of entity decomposition or the notion that entities can somehow be decomposed in the same manner that the activities of a functional area can be decomposed.
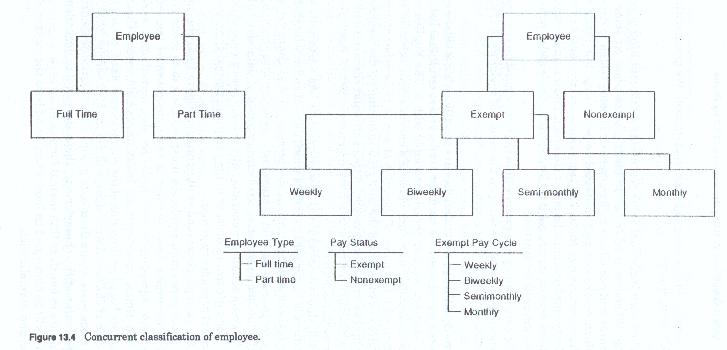
To continue our employee example, both employee type (full-time, part-time) and pay status (nonexempt, exempt) are independent first level characteristics, since all employees will be either full-time or part-time and will be either exempt or nonexempt.
If, for the sake of illustration, all part-time employees were paid weekly, but full time employees had a choice of pay cycle, then pay cycle (weekly, biweekly, semimonthly or monthly) would be dependent only on the value full-time. Figure 13-4 illustrates the concurrent classification of the employee entity by both employee type and pay status.
Rules governing characteristics
The values of a characteristic must be exhaustive, and mutually exclusive. That is, the values of a characteristic must cover all possible conditions, and two values of the same characteristic can not apply to the same entity. Each entity occurrence of an entity group must have one and only one value from the list of values, each entity must have a value, and no entity within the group may be missing a valid value. For instance, the characteristic sex of employee (male, female) is both mutually exclusive and exhaustive. The values both, other, all others, or unknown are not valid values for a characteristic. An individual characteristic value cannot include the connectors and or or. Characteristic values should wherever possible be a single word, or at worst a two word phrase.
The list of characteristic values may not have an explicit or implicit and between individual terms. On the other hand the list of characteristic values must always have an implicit or in its list of terms.
Each intensional characteristic at the first level must completely divide up the entire population of the family. Each value of each intensional characteristic forms the name of one of the divisional groups and heads its own independent chain. The use of additional dependent intensional characteristics further group the members of the value dependent entity group represented by each chain.
The concept of mutual exclusivity can be illustrated as follows:
French language proficiency (read, write, speak) is exhaustive, but not mutually exclusive, since a person can have proficiency in reading, writing and speaking.
Uses of Characteristics
Characteristics serve a number of distinct purposes.
First, their values can be tested to distinguish one entity family from another (using extensional characteristics), and within an entity family, one entity group from another (using intensional characteristics). We group entities for the following reasons:
For instance:
The entire family or a group within the family must be sequenced for reporting purposes based upon the values of one or more characteristics
Second, although characteristics are usually coded attributes, these codes are surrogates for a condition, state, or test result that has an English language word or phrase associated with it. The English word or phrase associated with each value of a characteristic (alone or in combination with the name of the value of one or more other characteristics) gives us the name of the entity group containing the members who have that value (or those values) of that particular characteristic.
In the above example we have two named groups - exempt employees and nonexempt employees.
Third, characteristics stand as surrogates for and are usually keys or identifiers of larger groups of data which depend entirely for their existence (existence dependent) on the presence of that characteristic. In many cases, each specific characteristic value implies the need for a specific (unique to it) set of attributes or group of data elements, one specific group of data per characteristic value. These groups of data are called data groups, records, or in the relational context they are called functional dependency groups.
In the example above (and as illustrated in figure 13-5), the business data about nonexempt employees must include a data group which is used to determine how overtime is to be compensated (agreed upon work week, agreed upon work hours per day, agreed upon work start and end times, rates/overtime hour, rates/shift, etc.)

These data groups are based on the value of the characteristic itself, or on a unique sequence of characteristic values, and are in third normal form.
In those cases where these data groups are existence dependent on a specific value of the characteristic, these single value dependent data groups are in fourth or fifth normal form.
This will be elaborated on later when we address the topic of classification and normalization.
Defining Characteristics
The data model uses characteristics to group entities into families and groups within families. Each entity must have some distinguishing characteristic which determines its family and group membership. These characteristics could be used to form a data equation of the form:
entity = f(characteristic (1), characteristic (2), ..., characteristic (n))
The definition of each characteristic must describes its function, role or in identifying family or group membership, and what particular aspect of the entity it relates to. The definition must also describe why that particular characteristic is used and where its values originate.
The definition of a characteristic should indicate why it is used. A suggested form for the definition of a characteristic is as follows:
The list of values of the characteristic (name of characteristic) are:
The following statement should be added when the characteristic is dependent to another characteristic:
The characteristic (name of characteristic) further qualifies the characteristic (name of characteristic).
where: (name of the characteristic) is the English name of the list of values
(what is being delineated) states what aspect of the entity is being described.
(name of entity) is the name of the entity family.
For example:
The characteristic pay cycle further qualifies the characteristic pay status.
The three goals of the data model
The data modeling process must accomplish several goals.
The first goal is to determine the labels of the major families of entities within the firm. A family of entities - or an entity family - is that group of entities whose members share one or more meaningful (to the firm) characteristics that separate those members from all other entities.
The second goal of the data model is to determine the composition of each family and to determine the data the firm must collect about the family members.
The third and final goal of the data model is to determine how the data should be grouped for maximum efficiency and maximum utilization.
The first goal of the data model
The activities associated with the first goal distinguish one family of entities from another. That is they define the scope and boundaries of each entity family. These activities are extensional (entity family outward), or inter-family analysis activities, and use extensional characteristics.
The achievement of this first goal - the identification of these entity families - is the primary product of the conceptual phase. This phase creates a definition of that entity family that describes why the group was formed and why the group is meaningful to the firm.
The model also attempts to identify those groups that are interrelated. That is those combinations of groups which need to be cross references with each other or which need to be used in combination with each other. For example, the firm must maintain records that reflect where each employee works (a cross reference between the records pertaining to the employee and the records pertaining to a location).
In order to maintain a manageable number of entities, the data model attempts to achieve a balance between entities whose definitions are so abstract that they include entity occurrences that are not of interest to the firm (i.e. all people) and entity definitions that are so discrete or narrow that the cannot be effectively managed or processed since they form a myriad of groups each of which contains a very small population of members. To achieve this balance, the documentation of the firm must be examined and the employees of the firm must be interviewed to determine the labels of the different groups of entities that are used or referred to by the members of the firm in actual practice.
To place this problem in perspective, we can look at the basic form of the entity definition:
An (label of the entity family) is a (real or logical person, place, thing, concept or event) that:
where:
characteristic (n) is something the entity must be, or must do. A characteristic must have a range of discrete values which are testable.
An example of such a definition might be:
A contract (the label of the entity family) is a legally binding written statement of agreement (the entity family is a collection of things, in this case documents) between the firm and a customer obligating the firm to provide one or more products and/or services to the customer and obligating the customer to pay for those products and/or services provided (the list of characteristics a contract must have).
The entity family here is contract. This definition answers the questions: What is the label of the entity family? What category of entity is it (person, place, thing, etc.)? What are its characteristics or in other words, what is a contract?
The answers may be explicit or implicit in the definition. In the above case: A contract must be written (it must be a physical document as opposed to an oral agreement). It must be agreed to by both the firm and its customer. It must be legally binding. Only one customer to a contract. Contracts cover both products and services. Contracts must state the price or prices (and other fees) to be paid for the products and services .
There is another whole group of documents which meet some of the above criteria. They are written. They are legally binding. They are statements of agreement. They cover both products and services. They state the price or prices and other fees to be paid for those products and/or services to be provided.
The difference between the two groups of documents is that the first is between the firm and its customers (a sales contract) and the second is between the firm and its suppliers (a purchase contract).
This definition allows the design team to know precisely (although many descriptive questions must still be resolved) what kind of documents qualify as a contract (sales contracts do) and what kind of documents do not qualify (purchase contracts do not). Note that both kinds of contracts must be documents since under either of the above definitions it must be a written agreement.
Note also that each of these characteristics as stated in the definition can be converted to a test which can be applied to a document to determine whether it is or is not a contract. Note also that a subtle change in wording in the second set of criteria or tests make it appear almost identical to the first set of criteria. The differences is that in the second no reference is made to either customers or the firm - the parties to the contract - nor who is obligated to do what.
Had the original definition been altered in that manner, both sales and purchase contracts could have been included, since they have a highly similar set of characteristics (both are contracts). In that case the entity family would have truly been contract and it would have been composed of two major entity groups - sales contracts and purchase contracts. As written however, Contract is limited to Sales Contract and Purchase Contracts (or whatever they will be called) is segregated to an entirely different entity family. In our example above, it was corporate policy that determined that contracts and purchase contracts were to be treated differently, and it was corporate policy that determined what constituted a contract (its definition).
The definition does not provide the answers (although it could) to the questions: How many different kinds of contracts are there, are they all treated the same way, and most important what kind of information does the firm need to capture, maintain and record about each contract. The answers to these questions are the second goal of the data model.
The second goal of the data model
The traditional definition of an entity includes the requirement that an entity must be something about which the firm must collect and maintain data. The second goal is to determine what data the firm must collect about each entity.
Since the term entity must always be qualified the entity the firm collects data about are the individual members of the each entity family. Since an entity family is composed of many members, and since it would be impractical to collect an individualized set of data about each member, the data model attempts to analyze the member entities to identify that data which is common to all members, and to identify that data which is common to groups of entities within the family. In doing so the process of attribution (determining what data the firm must collect about each entity) is simplified.
The activities associated with the second goal determine how, why and when the firm must distinguish the members of a given family from each other in other words, what the major groups are within the entity family. These activities must also determine how the members within each group are to be described. That is, what does the firm need to know about these kinds of entities, and do the differences between them also imply descriptive differences. These activities are intensional (family inward) or intra-family analysis activities.
These activities are aimed at identifying each, and every, intensional characteristic of interest to the firm, the list of values associated with each characteristic, and the chains of dependent characteristics which would be necessary for correct and efficient processing.
The third goal of the data model
The third goal of the data model is to determine the characteristics which determine proper grouping of the data which describes the entity family and the entity groups. These three goals are in effect the three levels of the data model - determine the families, determine entity groups within the family, determine the data group which describe the entities within the family.
In all cases things are grouped together because they are different in some ways from other things (which are also grouped together). In the data model these differences are reflected by differences in data. That is, each characteristic represents or is a surrogate for a collection of data which exists because that characteristic exists. Each characteristic value forms a group because that characteristic also represents a different group of data, or data which must be treated differently because of the characteristic value. These data groups are needed to qualify, support and expand on the condition or aspect denoted by the characteristic values.
Data Analysis, Data Modeling and Classification
Written by Martin E. Modell
Copyright © 2007 Martin E. Modell
All rights reserved. Printed in the United States of America. Except as permitted under United States Copyright Act of 1976, no part of this publication may be reproduced or distributed in any form or by any means, or stored in a data base or retrieval system, without the prior written permission of the author.