
Entity Identification
Data modeling has two major objectives. First, to identify the data requirements of the business and second, to organized and arrange that data for efficient processing and storage. Processing in this context means collecting and preparing that data for processing, processing the data, and preparing reports from that data. The sources of business data are both internal, within the firm, and external to the firm. Internal data predominantly reflects the activities of the employees of the firm as they interact with each other to produce the products and services of the firm, or as they record the results of their actions for either management use or for future reference.
External data predominantly reflects information collected about the people, places and things that the firm's employees interact with, events that take place, or records of business transactions which initiate internal activities of the firm.
For all firms (public and private, government and commercial), the normal course of doing business (regardless of the actual business itself) results in the generation of a vast number of forms and other business records. These records reflect the business transactions that transpired, the actions of firm personnel, and the information collected and stored for current and future reference. The collective data and information contained in these records constitute the data base of the firm.
The sheer number, complexity and interrelated nature of these business records, if not properly and consistently organized and cross referenced, could easily inundate the firm. All firms have therefore created systems for organizing, categorizing, classifying and storing business records in a manner such that they can be retrieved for later reference and use. All systems begin with a scheme for segregating the records by major category or group. These data organizing activities hold true for all firms regardless of whether their business records are stored manually, electronically or some combination of both.
In most firms the majority of the systems or schemes used for organizing these business records were developed using a personal, or local perspective, and in other areas of the firm, and in other areas a common, centralized or partially centralized perspective was used. Thus, with a firm, any given set of records may used by a relatively small group of persons, or a relatively large group of persons. Rarely, however can the same set of records used by all personnel within the firm.
Firms today are attempting to reduce data and information acquisition, maintenance and storage costs, improve productivity and improve information access by centralizing storage of commonly used records such as those contained in central account files and those used for central reference, etc., such that the same set of records can service largest population of persons. This process is made more difficult by to the need to accommodate the many diverse business perspectives and data retrieval needs of large populations with differing need for the same records.
Business data modeling and the models which result from that process attempts to develop a categorization, classification and data storage scheme for the firm based upon an analysis of the firm's data requirements, the characteristics of the firm's data and on the integration of the various views and perspectives of the functional areas of the firm which collect, maintain or rely on that data. This classification and categorization however, depends upon first having developed a clear understanding of those things the firm must collect data about.
Beginning the data model
Data analysis and data modeling are not separate processes. Nor is one the result of the other. The data model is both the product of the data analysis effort and the primary method by which the data analysis is performed. Data analysis is a process of continuous refinement of concept, description and definition which begins with business concepts and ends when the analysis team has determined the actual data elements needed to describe those concepts and the specific organization of those data elements for processing and storage.
The data analysis process will produce the specifications of one or more data files, each of which contains one or more records. These records contain reference material about the people, places and things of interest to the firm, and they contain the records of actions taken by and against those people, places and things. Whether these records are manual or automated, on a large corporate computer or a desktop personal computer, each record must be uniquely identifiable so that the data contained within it can be distinguished from all other records in that same file. The method of identification may be a single data item (such as a purchase order number) or multiple data items (such as a customer's name, address and telephone number.) This implies that each person, place, thing, or concept occurrence be identifiable and be capable of having an identifier assigned to it. This in turn implies that we be able to distinguish one occurrence from another. This ability to distinguish one occurrence from another is relatively easy when we are dealing with tangible items, and much more difficult when we are dealing with concepts. In many cases concepts exist only as a description or text and have no descriptive attributes.
Any filing system is only as good as its retrievable capability. That is, we develop data filing systems that can store tremendous amounts of information but if we cannot retrieve specific information for a specific purpose, those systems are useless. Moreover, we should also be able to rely on the accuracy and completeness of that information. We should be able to rely on the timeliness of the information and its consistency.
Certain rules and procedures have been established and certain methods have been developed which if followed, will ensure that we achieve these goals. The first rule is that each file, and thus each record in each file, should reflect data about a specific subject. Conversely, all data about a specific subject should be in one and only one file. Each record within a given file should reflect information about a specific occurrence of that subject. To illustrate:
Thus the first task of the data analysis process is to identify the subjects of that analysis. The first step of identification is to name these subjects. Using the above illustration we have a file of information about employees and therefore our subject is employee.
The second step, that of developing a definition for each subject usually reveals that most firms do not have a clear understanding of who and what these commonly used terms represent. It is not enough to design a file to contain information about a subject, and to design records to contain information about instances of that subject. We must have sufficient information about that subject to determine when we have identified a candidate for entry into the file. In other words, we must be able to recognize an employee, or a competitor, or a customer, or a technology when we see one, so that we can record information about it into the files. It is during the definition step that most of the problems arise, and that most of the mistakes are made. In addition, to ensure that our record keeping system is as robust as possible, and that it is a flexible as possible, we must ensure that we have accurately identified the scope of each of the groups represented by the labels. To extend our illustration, we must determine what kinds of people (or things) our file will have to keep records about.
What is an entity?
Before we continue with the process of identification and definition, we must understand some of the concepts which underlie the data modeling task. Specifically we must understand the concept of an entity, and in particular how that concept is used within the data modeling framework. We have used and will continue to use the term entity when discussing the major component of our models. For this discussion it does not much matter whether we are talking about entity families, groups or occurrences. Just what is an entity? As we have stated several times previously, the term entity literally means a fact of existence. The existence of something apart from its attributes. In other words, an entity is a term we use when we either have not yet assigned another name or when we are dealing with a group of undefined objects.
We do not model entities as such. Entities are stand-ins for other things. They are place holders. Entities are empty boxes. They are nothing in and of themselves. An entity is a void. We could have called them objects or things, or blobs. The term entity is nothing more than a name we apply when we refer to an indeterminate and undefined concept. All that can be said of an entity is that it exists (figure 12-1). Strictly speaking then, once we place a name in that empty box, we have ceased to model entities and we have begun to model something else. That something else is the something that is represented by the label we attached to it. Thus the entity is the starting point of our data model. However the term entity is also used as a general term when referring to these objects of business interest and is used almost synonymously with the terms object, thing, something, etc. The term entity is used as a nonspecific term when we do not wish to be more specific, or when we cannot be more specific.
|
Figure 12-1 Entities can be ...
The assignment of a label, or a name to an entity, to this empty box is the beginning of the process of data modeling. We still have not necessarily expanded our knowledge of that something. Because data analysis is the processing of file design, and more specifically record design, we can make certain assumptions. First, the something, (we shall continue to call it an entity for convenience) represents a collection or group of instances all of which can be refereed to by the same label. We have not said anything about what those some things look like, or whether they are all the same or they are all different (figure 12-2). We also have not said anything about how they will be described, or how they must be described.
|
Figure 12-2 Entities must be ...
The identification of an entity (figure 12-3) does not make any representations as to the to whether the occurrences within the group are highly similar, or highly dissimilar. All we can say at this point is that they label we have used can be applied to all of the occurrences equally.
|
Figure 12-3 Entity Identification
We have not even made any representations as to whether the firm is interested in these somethings, or why it is interested. We have not even determined whether the firm is interested in all the occurrences or just some of the occurrences. In other words by giving a label to a group of somethings, entities, we have made no representations as to the size of the group, nor have we made any representations as to the composition of that group. We do not know what kind of things make up the population of the group, and without that knowledge, we cannot effectively make any decisions as to what we need to identify or describe the members of that group (figure 12-4).
|
Figure 12-4 Thus to understand an Entity ...
Without knowing the extent of the group or its composition we cannot even determine the kind of identifier which can be used to distinguish one member of the group from another, nor can we determine whether all members of the group can be identified at all. In the data modeling context however we have added to the definition of an entity several qualifiers, first that it must be of interest to the firm, and second that we be able to collect and maintain data about each instance in the group. Therefore we can make the assumption that these entities are of interest and that we can collect data about them, and thus our task is to determine why the firm is interested in the entity, what kind of data it requires about the entity, and later on we must determine how much of the data that is required can actually be collected.
In its first stages, entity analysis concentrates on the population of the overall group or entity family. The members of the entity family are the subjects of the file that must ultimately be constructed and the records of that file are records which describe and provide information on those members. Until the members of the family have been determined, no determination can be made as to what those records must look like. That is, no determination can be made as to which data items they must contain.
Identifying the entity family requires that we determine and document what criteria can and must be used to determine when a member is part of the group. That is, if we have decided that one of our entities is called "employees" then we must be able to determine, without ambiguity, when a particular person is, or is not an employee. We must be able to state with a high degree of confidence that a given person is an employee because that person meets a given set of criteria. This is a binary condition, it either meets the criteria or it does not. This binary condition hold true for all entity definitions. Without that information we would not know when to create a record about something, or whether that something belongs in our file.
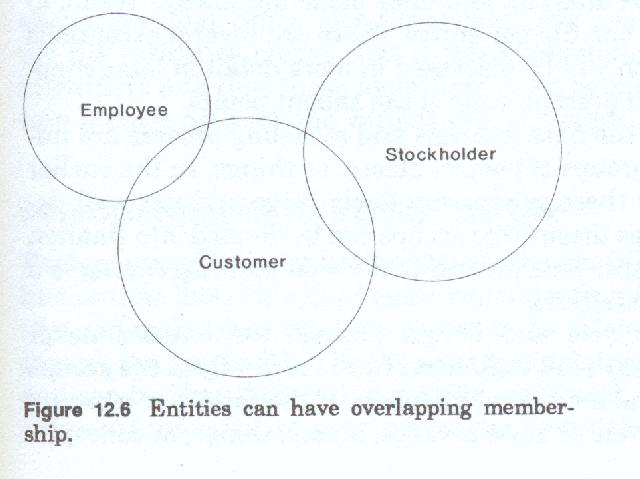
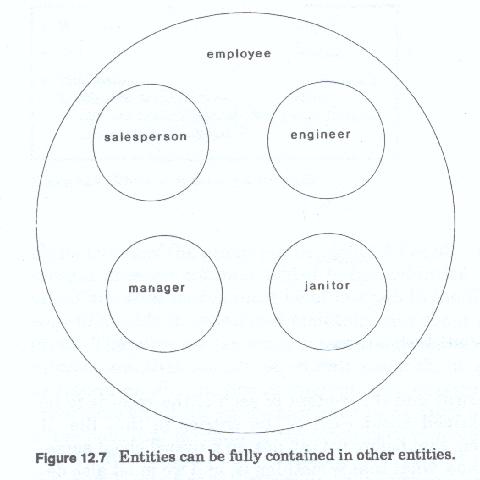
The end result of process of data analysis and the production of the data models, is the creation of a file, containing a set of records on each instance, each individual, defined as a subject of that file. The data modeling process thus is twofold. First to determine the scope and membership of the group or population of subjects which are to be contained in the file (figure 12-5). Second, to determine the kinds of records and the content of each of the records to be developed and maintained about each of the entries in that file. It should be obvious then, that before we can design a record about something we must first know what that something is, and we must also determine how many, and what kinds of variations there are about those somethings (figure 12-6).
To illustrate:
The terms file and entity have been used interchangeable in the preceding discussion. Data analysis and data modeling always result in the creation of at least one file per entity. There are several exceptions to this statement, which will be discussed in more detail in later chapters but for now we will present some of the salient points.
The entities used in the data analysis and modeling process are understood to be sets or groups of people, places or things. In the earlier phases of the analysis these groups are fairly large and not well defined. In almost all cases these large groups can be divided into smaller more well defined groups. This process of division and regrouping is a natural product of the analysis.
Throughout the analysis and design phases, the entities never change. The analysts may shift their focus from the family to the groups within the family, to the individual members of the family or a group, but the entity remains one or more persons, places, things or concepts. The records which result from the models of the final phases are not entities, rather they are descriptors of entities. They represent the attributes used to describe the entities. They are to the entity, what the employee application is to the employee - a set of records, a collection of information used to used to record items of interest about the entity itself.
The final product of the analysis is a set of records designed to contain the information about each member of these sets, and the records are designed such that any variations in description, or information requirement can be accommodated.
The analysis team must always remember that regardless of the size of the group, groups are composed of individual members or instances. Although many filing systems have been devised which contain duplicate records of occurrences which can be filed in multiple files, to maintain an effective system of records, any given person, place or thing, should have a single place, or file within which the records about at are kept. This is made more difficult in cases where someone or something plays multiple roles simultaneously, such as when a person is an employee, a customer, and a stockholder all at the same time. By recording the information only once, the firm can make a change to the information about that person once and only once. A single set of records about a given occurrence, has the effect of eliminating redundancy and inconsistency of information. This maintains data integrity, but makes the design process much more difficult. These statements notwithstanding, the firm may not always know when these multiple file resident conditions exist, but they can identify the potential for their existence. The firm must decide how it wishes to handle it, and it must know the consequences of each alternative. If the choice is to duplicate information, then the firm must resolve the issues associated with maintaining synchronization between the various records, in the various files, on the same occurrence.
Single file residency allows the firm to assign a single identifier to each individual. Since each file should have a unique identifier multiple file residence means that a given occurrence must have multiple identifiers and that those identifiers must be known in order to maintain linkage between the various sets of records.
Development of the data entity time line
Each entity of interest to the firm can be described in terms of its life line or time line. This line begins when the firm first recognizes the entity and ends when the firm ceases to be interested in the entity. Although the start of this line is usually a relatively fixed point in time, and can be identified with a specific event such as receipt of the order or the identification of an employee candidate, the end of the line is usually much less defined. In many cases the firm may not have identified a specific event where interest ceases and the file for some of the entities may continue indefinitely. Between beginning and end, start and finish, other events happen randomly.
The entities themselves are dynamic. The information about them is constantly changing. These changes occur randomly. Changes may originate within the firm as it does something to the entity or it may originate outside the firm when the entity itself or some other entity does something which changes some aspect of the entity.
The definition and understanding of the entity life line however is critical during the analysis of the entity. Most entities, most people, places and things, do not exist in a single state or single role. They past through many states during their life. Life in the context of this use begins when the firm first recognizes the entity and ends when the firm is no longer interested in it. During its life an entity instance usually has only one role, however in some cases a given entity instance may play multiple roles at the same time. This complicates the analysis since the design must account for this multi-state condition.
The life lines will also help the analysis team to understand the various aspects of each entity under study.
Entities of interest to the firm
We have used the phrase "entities of interest to the firm" consistently. In order to understand the time line concept we have to further define what we mean by entities of interest to the firm. Obviously, not all entities are of interest to the firm. The firm is only interested in those entities with which it interacts, or which it uses in the course of its business transactions. Further, the firm is only interested in those instances of those entities to which it is specifically related. In other words the firm is interested in vendors but only those vendors from whom the firm buys items, would like to buy items, or has bought items in the past. In some cases the firm may also interested in vendors from whom the firm would like to avoid ever buying items.
To continue the example, for each vendor of interest to the firm, there are many things which could be known but there is a limited subset of those things (attributes) which the firm actually wants to know. This subset of "want to know" things, may be further limited by what the firm actually needs to know. The basic design for the new system must include the "need to know" items, should include the "want to know" items, and could include as many of the "would like to know" items as resources permit.
There are many things which can happen to the vendor, which change it, however the firm is only interested in those changes which relate to its interaction with that vendor.
In many cases, in fact most cases, the firm is interested in a specific entity instance only within a specific time window. Within that time window however the entity may not always be the same, nor act the same. For instance:
In other words, are the candidate, the employee, and the terminated employee the same entity or are they different? The answer to that question determines how many named boxes appear on the entity model. The answer to that question also determines how many different sets of records, how many different identifiers and how many record keeping systems are necessary. It also raises several questions which must be answered, primary of which is how will the firm maintain the records as the person moves from role to role?
In order to determine the extensional limits of the entity, one useful technique is to construct an entity time line.
Producing a Data Entity Time Line
For each entity of interest (not entity instance) we start with a straight line to represent the entity time line. On this line we indicate each of the states or roles that the entity can play, and each of the states that the entity can exist in during its life. These states and these roles should be indicated on the life line in the sequence in which they occur. If the entity can occupy several roles simultaneously, or move in and out of a given role the roles should be indicated as parallel life lines. The difference between states and roles is that an entity can occupy only one state at a time, whereas an entity can occupy several roles simultaneously. An entity passes through its possible states in a fixed sequence whereas it can occupy a role randomly.
If we treat the members of the data entity set generically, without regard to their individual idiosyncrasies, or differences, we can expect that what can happen to one member of the set can happen to any member of the set and thus can happen to all.
However most entities in the corporate environment are not simple entities. That is they are not homogeneous in nature, they do not all look, or act the same, nor are they all treated the same. There are different categories of employees, customers, vendors, products, orders, etc. The people entities may interact with the firm in a series of roles. A person interacting in one role may cause things to happen, or have things happen to it, which could not happen to the same person interacting in a different role. The most common examples of these types of roles, are salespersons and management personnel.
The library analogy
One complex example of entity identification exists within the public libraries. If we were to build a data model of the library, several entities would be relatively obvious - the library customers, the library shelves, other libraries (for inter-loan) the suppliers of the things which are loaned, and that which the library loans. The shelves, customers, suppliers and other libraries are relatively easy to identify, and define. That which the library loans is not as easy to identify or define. What single label can we apply to those diverse items. Libraries today loan a wide variety of items ranging from book (paperback and hardcover) records, tapes, CD, video tapes, periodicals, and in some cases works of art. There is not single term which applies except perhaps inventory or collection. Each of these things is part of the inventory or collection of the library, and can be defined as inventory or collection, even though the items themselves are substantially different. When we use the collection or inventory as an entity however we must always remember that we are not going to be describing the collection as a whole, but rather the individual components that make it up.
Each of these components has something in common, in that is something that is loaned out or that can be used within the library itself (as is usually the case for reference works) but each is also different. We can group the collection several different ways, and we can shelve the items several different ways but (ignoring duplicates) a particular item has to have one and only one place to be shelved, even though it may belong to several different categories. The designers of library shelving systems have to allow for a patron to locate a particular item by some aspect or characteristic of its content an not just by its name, or shelf number. It is this need to locate by content, even when the identifier is not known that makes classification and grouping of data such an important part of the data analysis and data modeling process.
The entity family called collection is not made up of a homogeneous group of items and in a sense the entity family is more of an entity cousins club than anything else. The data modeler must analyze this entity and determine how to deal with these loosely coupled groups of things which are different and yet which must be treated the same for certain business processes.
Defining the entity
The definition of an entity should answer the following questions:
The definition statements should follow the form:
In the preceding form, (name of entity) is unique, and descriptive of the distinguishing characteristics. It should be a noun or noun phrase. A noun phrase must have a noun and may include adjectives and participles. Prepositions may also be included for clarity.
The name of an entity is a label for a set of data. Entities may be grouped in families. Unique labels are applied to the family as a whole, to groups of entities within the family, or to individual members of the family. Individual family members are distinguished by separate labels because they have different relationships and/or characteristics.
A(n) (name of entity) has the following distinguishing characteristics: (characteristic (1), characteristic (2), ... characteristic (n)).
In the preceding form a distinguishing characteristic is a feature or property of the entity that sets it apart from its siblings. Siblings are entities that are children of the same parent.
Data Analysis, Data Modeling and Classification
Written by Martin E. Modell
Copyright © 2007 Martin E. Modell
All rights reserved. Printed in the United States of America. Except as permitted under United States Copyright Act of 1976, no part of this publication may be reproduced or distributed in any form or by any means, or stored in a data base or retrieval system, without the prior written permission of the author.